SQL Engine Source Parsing
SQL Engine Source Parsing
Query Optimization
The query optimization process of the openGauss database is clear. From the perspective of source code organization, related code is distributed in different directories, as shown in Table 1.
Table 1 Description of the query optimization module
As the SQL language is diversified and flexible, the SQL statements written by different developers vary according to their experience. In addition, the SQL statements can be automatically generated by tools. The SQL language is a descriptive language. A database user only describes a desired result, and does not care about a specific data obtaining manner. The SQL language entered into the database is usually not in their optimal forms, and may include some redundant information. Mining this information could improve the exaction efficiency. Query rewriting is to convert SQL statements entered by users into more efficient equivalent SQL statements. It has two basic principles.
- (1) Equivalence: The output of the original statement is the same as that of the rewritten statement.
- (2) Efficiency: The rewritten statement is more efficient in execution time and resource usage than the original statement.
Query rewriting is mainly equivalent transformation based on relational algebra. This transformation usually meets the laws of commutativity, associativity, distributive, and decomposition, as shown in Table 2.
Table 2 Equivalent transformation based on relational algebra
Query rewriting can achieve optimization based on relational algebra theories, such as predicate pushdown and subquery optimization, or based on heuristic rules, such as outer join elimination and table join elimination. In addition, there are some optimizations related to a specific optimization rule and an actual execution process. For example, based on parallel scanning, consider to execute an aggregation operator by phase. Aggregation is divided into different phases, to improve execution efficiency.
From another perspective, query rewriting is equivalent transformation based on optimization rules and belongs to logical optimization, which can also be called rule-based optimization. How do we measure the performance improvement of an SQL statement after query rewriting? It is very important to evaluate query rewriting based on costs. Therefore, query rewriting can be not only based on experience, but also based on costs.
Taking predicate transfer closure and predicate pushdown as examples, predicate pushdown can greatly reduce the calculation workload of upper-layer operators to achieve optimization. If the predicate condition has equivalent operations, then equivalence inference can be implemented by equivalent operations, so as to obtain a new selection condition.
For example, if two tables t1 and t2 each contain a total of 100 rows of data [1,2,3, ..100], the query statement SELECT t1.c1, t2.c1 FROM t1 JOIN t2 ON t1.c1=t2.c1 WHERE t1.c1=1 may be optimized by select pushdown and equivalent inference, as shown in Figure 1.
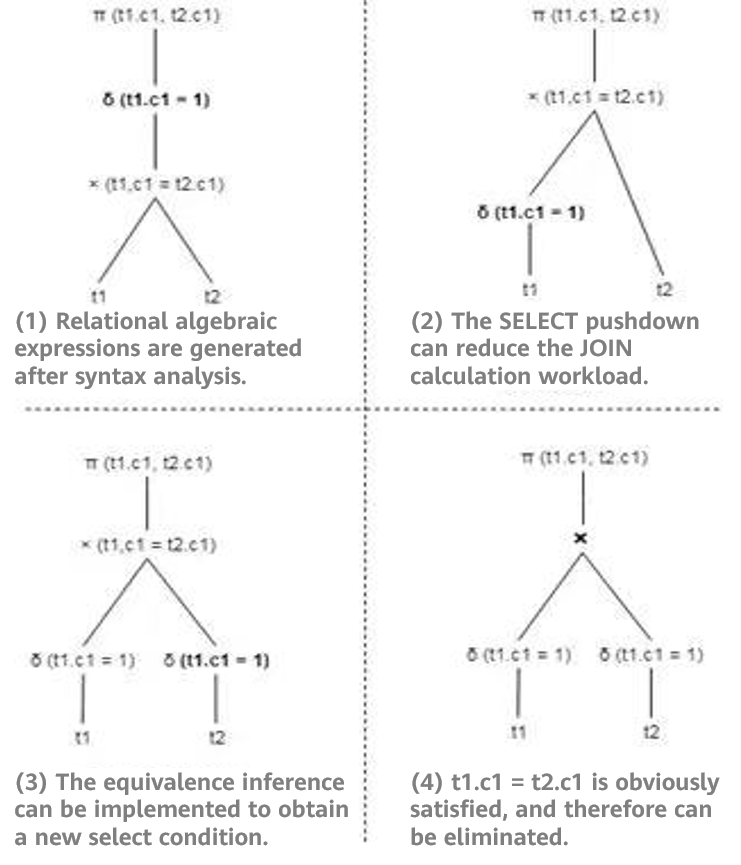
Figure 1 Comparison before and after query rewriting
As shown in Figure 1 (1), 100 rows of data in tables t1 and t2 are scanned and joined to generate the intermediate result, and then the selection operation is performed. The final result contains only one row of data. If equivalence inference is used, it may be obtained that values in {t1.c1, t2.c1, 1} are equivalent to each other. Therefore, a new selection condition of t2.c1 = 1 is deduced, and the condition is pushed down to t2. In this way, the rewritten logical plan in Figure 1 (4) is obtained. As shown in the preceding figure, the rewritten logical plan only needs to obtain one piece of data from the base table. During join, there is only one piece of data in the inner and outer tables. In addition, the filter criteria in the final result are not required, greatly improving the performance.
At the code level, the architecture of query rewriting is roughly shown in Figure 2.
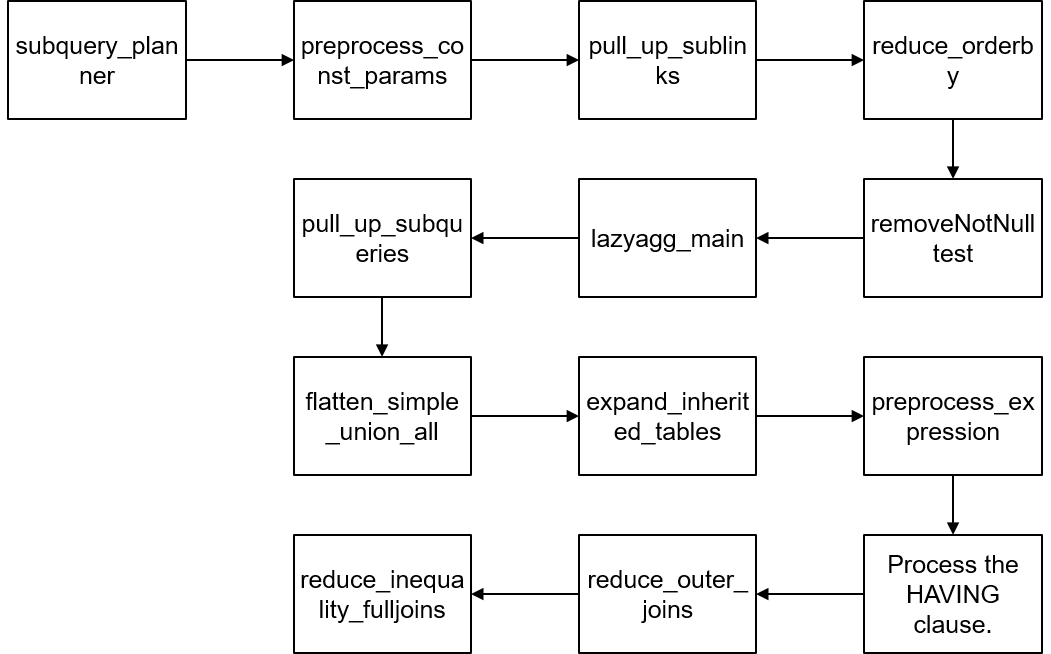
Figure 2 Architecture of query rewriting
(1) Pulling up a subquery: When a subquery appears in RangeTableEntry, it stores a subquery tree. If the subquery is not pulled up, a subquery execution plan is formed after query optimization. The upper-layer execution plan and subquery plan perform nested loops to obtain the final result. In this process, the query optimization module does not have so many optimization choices for the subquery. If the subquery is pulled up, it is joined with tables at the upper layer.
(2) Constant replacement: Because the constant reference speed is faster, the variable can be replaced by the calculated constant. The implementation function is preprocess_const_params.
(3) Replacing common table expressions (CTEs) with subqueries: Theoretically, CTEs have the same performance as subqueries. However, subqueries can be further pulled up, rewritten, and optimized. Therefore, subqueries are used to replace CTEs. The implementation function is substitute_ctes_with_subqueries.
(4) Replacing multi count (distinct) with multiple subqueries: If this type of query occurs, multiple count (distinct) queries are replaced with multiple subqueries. Each subquery contains a count (distinct) expression. The implementation function is convert_multi_count_distinct.
(5) Pulling up sublinks: Sublinks appear in constraints such as WHERE and ON, and are usually used together with predicates such as ANY, ALL, IN, EXISTS, and SOME. Although sublinks are clear from the logical level of statements, the efficiency varies. For example, the execution result of a correlated sublink is related to the parent query. That is, each tuple of the parent query corresponds to the re-evaluation of the sublink. In this case, you can pull up the sublink to improve efficiency. In this part, ANY and EXISTS sublinks are pulled up to SemiJoin or Anti-SemiJoin. The implementation function is pull_up_sublinks.
(5) Reducing ORDER BY: In the parent query, database records may need to be reordered. Therefore, reducing the number of ORDER BY statements in the subquery can improve the efficiency. The implementation function is reduce_orderby.
(6) Deleting NotNullTest: Deleting related non-null tests can improve efficiency. The implementation function is removeNotNullTest.
(7) Lazy Agg rewriting: Lazy aggregation is used to reduce the number of aggregation times. The implementation function is lazyagg_main.
(8) A lot of work has been done to optimize the join operation to obtain a better execution plan. The implementation function is pull_up_subqueries.
(9) UNION ALL optimization: The UNION ALL operation at the top layer is processed to convert the UNION ALL set operation to the AppendRelInfo operation. The implementation function is flatten_simple_union_all.
(10) Expanding an inherited table: If an inherited table is used during the execution of a query statement, the inherited table exists as a parent table. The parent table needs to be expanded into multiple inherited tables. The implementation function is expand_inherited_tables.
(11) Expression preprocessing: This module standardizes expressions in the query tree, including replacing the alias Var generated by links, evaluating constant expressions, leveling constraints, and generating execution plans for sublinks. The implementation function is preprocess_expression.
(12) Processing the HAVING clause: In the HAVING clause, some constraints can be converted into filter conditions (corresponding to WHERE). The constraints in the HAVING clause are split to improve efficiency.
(13) Outer join elimination: The purpose is to convert an outer join to an inner join to simplify the query optimization process. The reduce_outer_join function is used.
(14) Full join rewriting: Rewrites the full join function to improve its functionality. For example, the statement SELECT * FROM t1 FULL JOIN t2 ON TRUE can be converted to SELECT * FROM t1 LEFT JOIN t2 ON TRUE UNION ALL (SELECT * FROM t1 RIGHT ANTI FULL JOIN t2 ON TRUE). The implementation function is reduce_inequality_fulljoins.
The following uses pulling up sublinks as an example to describe the most important subquery optimization in openGauss. A sublink is a special subquery. It appears in constraints such as WHERE and ON, and is often accompanied by predicates such as ANY, EXISTS, ALL, IN, and SOME. The openGauss database sets different SUBLINK types for different predicates. The code is as follows:
Typedef enum SubLinkType { EXISTS_SUBLINK, ALL_SUBLINK, ANY_SUBLINK, ROWCOMPARE_SUBLINK, EXPR_SUBLINK, ARRAY_SUBLINK, CTE_SUBLINK } SubLinkType;The openGauss database defines an independent structure SubLink for sublinks, which describes the sublink types and operators. The code is as follows:
Typedef struct SubLink { Expr xpr; SubLinkType subLinkType; Node* testexpr; List* operName; Node* subselect; Int location; } SubLink;Figure 3 shows the interface functions related to pulling up sublinks.
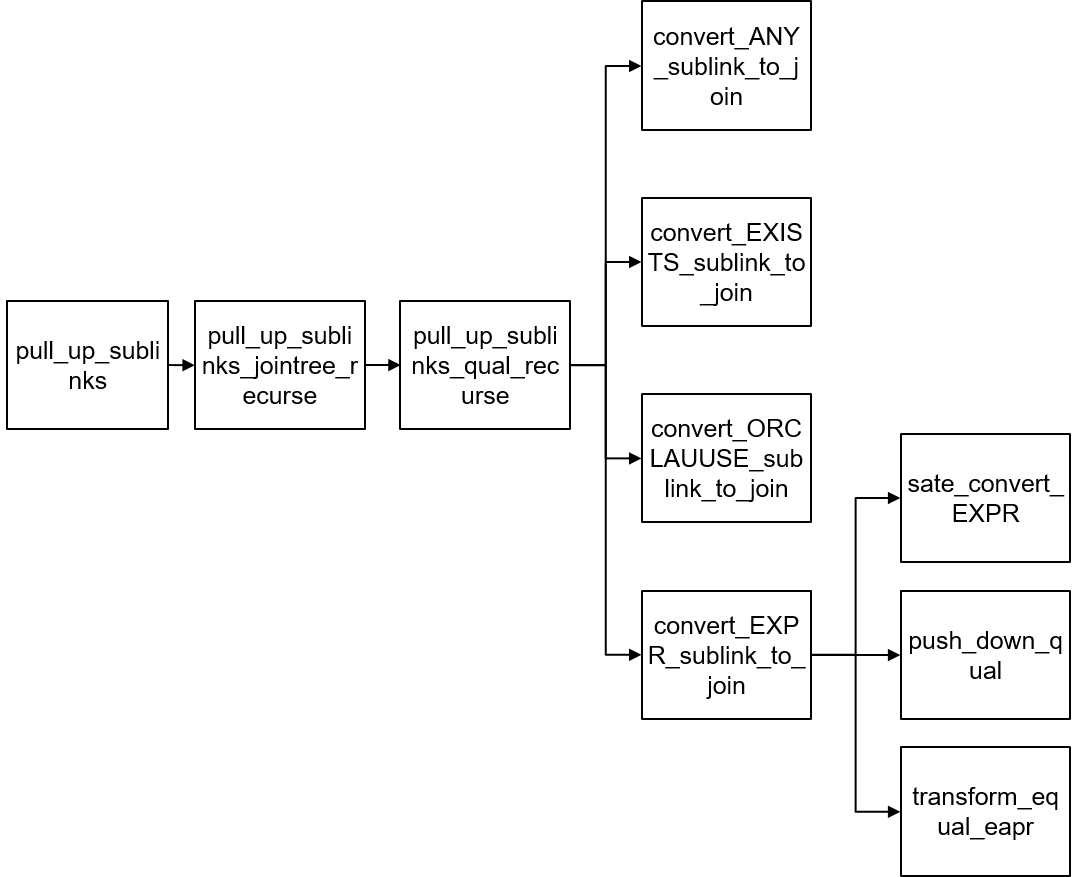
Figure 3 Interface functions related to sublinks
The main process of pulling up sublinks is implemented in the pull_up_sublinks function. The pull_up_sublinks function invokes pull_up_sublinks_jointree_recurse to recursively process nodes in Query->jointree. Table 3 lists the input parameters of the function.
Table 3 Input parameters of the function
There are three types of jnodes: RangeTblRef, FromExpr, and JoinExpr, which are processed by the pull_up_sublinks_jointree_recurse function separately.
RangeTblRef
RangeTblRef is a leaf node of Query->jointree and is the condition for ending the function recursion. When the program reaches this branch, there are two cases:
- (1) If the current statement is a single table query and has no join, the recursion proceeds until it ends. Then, the program checks whether the sublink meets other pull-up conditions.
- (2) If the query statement has joins, during the recursion of From->fromlist, JoinExpr->larg, or JoinExpr->rarg, when it traverses the RangeTblRef leaf node, relids (a set of tables) of the RangeTblRef node is returned to the upper layer to determine whether the sublink can be pulled up.
FromExpr
- (1) Traverse the nodes in From->fromlist recursively, and then invoke the pull_up_sublinks_jointree_recurse function recursively for each node until reaching the RangeTblRef leaf node.
- (2) Invoke the pull_up_sublinks_qual_recurse function to process From->qual and process ANY_SUBLINK or EXISTS_SUBLINK that may occur.
JoinExpr
(1) Invoke the pull_up_sublinks_jointree_recurse function to recursively process JoinExpr->larg and JoinExpr->rarg until reaching the RangeTblRef leaf node. In addition, check whether the sublink can be pulled up based on the join type.
(2) Invoke the pull_up_sublinks_qual_recurse function to process JoinExpr->quals and process ANY_SUBLINK or EXISTS_SUBLINK that may occur. The available_rels1 parameter of the pull_up_sublinks_qual_recurse function varies depending on the join type.
In addition to ANY_SUBLINK and EXISTS_SUBLINK, the pull_up_sublinks_qual_recurse function also performs query rewriting for OR clauses and EXPR-type sublinks. The code logic of pulling up sublinks of the Expr type is as follows:
(1) Use the safe_convert_EXPR function to check whether the sublink can be pulled up. The code is as follows:
//Check whether the current SQL statement meets the condition for pulling up the sublink. if (subQuery->cteList || subQuery->hasWindowFuncs || subQuery->hasModifyingCTE || subQuery->havingQual || subQuery->groupingSets || subQuery->groupClause || subQuery->limitOffset || subQuery->rowMarks || subQuery->distinctClause || subQuery->windowClause) { ereport(DEBUG2, (errmodule(MOD_OPT_REWRITE), (errmsg("[Expr sublink pull up failure reason]: Subquery includes cte, windowFun, havingQual, group, " "limitoffset, distinct or rowMark.")))); return false; }(2) Use the push_down_qual function to extract related conditions from the sublink. The code is as follows:
Static Node* push_down_qual(PlannerInfo* root, Node* all_quals, List* pullUpEqualExpr) { If (all_quals== NULL) { Return NULL; } List* pullUpExprList = (List*)copyObject(pullUpEqualExpr); Node* all_quals_list = (Node*)copyObject(all_quals); set_varno_attno(root->parse, (Node*)pullUpExprList, true); set_varno_attno(root->parse, (Node*)all_quals_list, false); Relids varnos = pull_varnos((Node*)pullUpExprList, 1); push_qual_context qual_list; SubLink* any_sublink = NULL; Node* push_quals = NULL; Int attnum = 0; While ((attnum = bms_first_member(varnos)) >= 0) { RangeTblEntry* r_table = (RangeTblEntry*)rt_fetch(attnum, root->parse->rtable); // This table must be a base table. Otherwise, it cannot be processed. If (r_table->rtekind == RTE_RELATION) { qual_list.varno = attnum; qual_list.qual_list = NIL; // Obtain the condition that contains the special varno. get_varnode_qual(all_quals_list, &qual_list); If (qual_list.qual_list != NIL && !contain_volatile_functions((Node*)qual_list.qual_list)) { any_sublink = build_any_sublink(root, qual_list.qual_list, attnum,pullUpExprList); push_quals = make_and_qual(push_quals, (Node*)any_sublink); } list_free_ext(qual_list.qual_list); } } list_free_deep(pullUpExprList); pfree_ext(all_quals_list); return push_quals; }(3) Use the transform_equal_expr function to construct a subquery to be pulled up. (Add a GROUP BY clause and delete related conditions.) The code is as follows:
// Add GROUP BY and windowClasues for SubQuery. if (isLimit) { append_target_and_windowClause(root,subQuery,(Node*)copyObject(node), false); } else { append_target_and_group(root, subQuery, (Node*)copyObject(node)); } // Delete related conditions. subQuery->jointree = (FromExpr*)replace_node_clause((Node*)subQuery->jointree, (Node*)pullUpEqualExpr, (Node*)constList, RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES);(4) Construct the conditions that need to be pulled up. The code is as follows:
// Construct the conditions to be pulled up. joinQual = make_and_qual((Node*)joinQual, (Node*)pullUpExpr); ... Return joinQual;(5) Generate a join expression. The code is as follows:
// Generate a join expression. if (IsA(*currJoinLink, JoinExpr)) { ((JoinExpr*)*currJoinLink)->quals = replace_node_clause(((JoinExpr*)*currJoinLink)->quals, tmpExprQual, makeBoolConst(true, false), RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES); } else if (IsA(*currJoinLink, FromExpr)) { ((FromExpr*)*currJoinLink)->quals = replace_node_clause(((FromExpr*)*currJoinLink)->quals, tmpExprQual, makeBoolConst(true, false), RNC_RECURSE_AGGREF | RNC_COPY_NON_LEAF_NODES); } rtr = (RangeTblRef *) makeNode(RangeTblRef); rtr->rtindex = list_length(root->parse->rtable); // Construct the JoinExpr of the left join. JoinExpr *result = NULL; result = (JoinExpr *) makeNode(JoinExpr); result->jointype = JOIN_LEFT; result->quals = joinQual; result->larg = *currJoinLink; result->rarg = (Node *) rtr; // Add JoinExpr to rangetableentry. In subsequent processing, the left outer join can be converted to an inner join. rte = addRangeTableEntryForJoin(NULL, NIL, result->jointype, NIL, result->alias, true); root->parse->rtable = lappend(root->parse->rtable, rte);
Statistics and Cost Estimation
In different data distribution, the execution efficiency of the same query plan may be significantly different. Therefore, the impact of data distribution on the plan should also be considered during plan selection. Unlike common logical optimization, physical optimization builds plan optimization on data and improves performance by minimizing data operation costs. In terms of functions, the physical optimization of openGauss involves the following three key steps:
(1) Data distribution generation: Mines data distribution from data tables and stores the data.
(2) Plan cost estimation: Based on data distribution, a cost model is established to estimate the actual execution time of a plan.
(3) Optimal plan selection: Based on the cost estimation, the system searches for the plan with the minimum cost from the candidate plans.
First, introduce the concepts related to data distribution and the internal storage mode of the database.
1. Data Distribution Storage
The distribution of dataset D consists of the frequencies of different values on D. Assume that D is the projection data in the Grade column of Table 4. This column has three values 1, 2, and 3. For details about the frequency distribution, see Table 5. Here, the number of Grade values is referred to as number of distinct values (NDV).
Table 4 Grade attribute distribution
Table 5 Grade frequency distribution
D may relate to a plurality of attributes, and distribution of the plurality of attributes is referred to as joint distribution. The value space of the joint distribution may be very large. From the perspective of performance, the database does not store the joint distribution of D, but stores the attribute distribution of D separately. For example, the database stores the frequency of {Gender='Male'} and {Grade='1'}, instead of {Gender='Male', Grade='1'}. This practice loses much of the information distributed on D. As will be seen in the subsequent section on selectivity and data distribution, openGauss will use prediction techniques to infer the joint distribution when the system requires it. Although, in some cases, the results of this speculation may differ significantly from the actual situation.
The data structure of data distribution is especially critical to understanding how the database stores this information. Generally, a key-value (KV) pair is the most commonly used structure for describing distribution, where key indicates a value, and value indicates a frequency. However, when the NDV is large, the expansion of the key value causes low storage and read performance of the KV. To improve efficiency, the openGauss uses the "KV vector + histogram" to indicate the attribute distribution.
Logical structure of data distribution: A high-frequency value frequency is stored by using a KV, and its storage structure is referred to as a most common value (MCV). A frequency other than the high-frequency value is described by using an equal-bin-count histogram (EH). In the implementation, the openGauss puts the k (k = 100) key values with the highest frequency into the MCV, and puts the other key values into the EH.
It should be noted that the EH combines the frequencies of multiple values, which significantly improves the access efficiency but also blurs the distribution. However, as can be seen in the following sections, the high frequency value is more critical to the estimation of the plan cost than the low frequency value. Therefore, this hybrid strategy, which trades for high performance at the cost of losing the accuracy of low frequency values, is undoubtedly a fairly cost-effective approach.
Storage location of data distribution: In openGauss, information such as the MCV and EH is stored in the PG_STATISTIC system catalog. Table 6 describes the table definition.
Table 6 Definitions of the PG_STATISTIC system catalog
One tuple in Table 6 stores statistics of one attribute. The following describes the attribute meanings of tuples.
(1) The starelid/staattnum attribute indicates the table OID and attribute ID.
(2) The attribute stanullfrac indicates the percentage of null values in the attribute. The value 0 indicates that the column has no null value.
(3) The attribute group {stakind1, stanumbers1, stavalues1} forms a slot in the PG_STATISTIC system catalog and stores information about a data structure type in Table 7. There are five slots in the PG_STATISTIC system catalog. Generally, the first slot stores the MCV information, and the second slot stores the EH information. Take the MCV slot as an example. The stakind1 attribute indicates that the slot type is MCV, and 1 is the enumerated value of STATISTIC_KIND_MCV. The stanumbers1 and stavalues1 attributes record the MCV content. The stavalues1 attribute records the key value, and the stanumbers1 attribute records the frequency corresponding to the key. In the preceding example, the frequency ratio for value 1 is 0.2851, and the frequency ratio for value 2 is 0.1345.
Table 7 Description of PG_STATISTIC
Note that data distribution and the content of the PG_STATISTIC system catalog are not automatically generated when the table is created. They are generated when the ANALYZE operation is performed on the table.
2. Data Distribution Extraction
This section describes the logical structure and storage of data distribution in the openGauss. How can we obtain data distribution information from data? The following describes the distribution extraction process in the openGauss. To deepen the understanding of the method, let's begin with analyzing the challenges.
The most direct way to obtain the distribution is to traverse all data and generate the MCV and EH information directly by counting. However, in practice, there may be a large amount of data, and the I/O cost of traversal is usually unacceptable. For example, the bill data of a bank involves hundreds of billions of records and is stored at the TB level. In addition to the I/O cost, the memory consumption of the counting process may exceed the upper limit, which makes the algorithm implementation especially difficult. Therefore, a more realistic approach is to reduce the scale of data analysis and use small sample analysis to estimate the overall data distribution. Then, the quality of selected samples is particularly important.
Currently, the sample generation process of the openGauss database is implemented in the acquire_sample_rows function, which uses the two-phase sampling algorithm to estimate the data distribution. In the first phase, an S algorithm is used to randomly sample a physical page, to generate a sample S1. In the second phase, a Z (Vitter) algorithm is used to perform reservoir sampling on tuples included in S1, to finally generate a sample S2 including 30000 tuples. The two-phase algorithm ensures that S2 is an unbiased sample of the original data. Therefore, you can infer the original data distribution by analyzing S2 and record the distribution information in the PG_STATISTIC system catalog.
openGauss divides sample generation into two steps to improve sampling efficiency. A theoretical basis of the method depends on the following practical condition: A quantity M of physical pages occupied by data can be accurately obtained, but a quantity n of tuples included in each physical page is unknown. Because M is known, the S algorithm may evenly sample a page by using a probability of 1/M, and may generate a small sample S1 of original data. Generally, a tuple belonging to any physical page is an equal probability event, which ensures that S1 is an unbiased sample. However, the total number of tuples in S1 is far less than that of original data, so costs of performing secondary sampling on S1 are greatly reduced. The main reason why the S algorithm is not used in the second phase is that the total number of tuples N of S1 is unknown (because n is unknown), and the sampling probability (1/N) cannot be obtained using the S algorithm. The Z (Vitter) algorithm is a reservoir sampling algorithm, which can ensure uniform sampling when the total amount of data is unknown. The principle of reservoir sampling algorithm is not the focus of this section. You can refer to related information by yourself.
3. Selectivity and Data Distribution
SQL query often contains the WHERE constraint (filtering condition), for example,** SELECT * FROM student WHERE gender = 'male';** and SELECT * FROM student WHERE grade > '1'. What is the actual effect of the constraint on the query result? In order to measure the effectiveness of constraints, the concept of selectivity is first introduced.
Selectivity: Given the query dataset C (which can be a data table or any intermediate result set) and constraint expression x, the selectivity of x relative to C is defined as follows:

Where, |C| indicates the total number of records in C, and |C|x indicates the number of records that meet the x constraint on C. As shown in Table 8, when x is "grade = 1", 3/5. 
Table 8 Selectivity of dataset C
Data distribution of C is denoted as π. It can be learned from the definition that selec(x│C) is actually a description of π according to semantic x. Data distribution helps calculate the selectivity so that the calculation process does not need to traverse the original data. In the cost estimation section, you will see that the selectivity plays a significant role in estimating the cost of a plan.
Based on this idea, this section will focus on the selectivity calculation in the openGauss. As the selectivity calculation under simple constraints is representative, this section will take simple constraints as an example for illustration. A simple constraint is defined as a non-range constraint that involves only a single attribute in the base table.
For details about the calculation method of non-simple constraint selectivity, read the source code in this chapter.
Selectivity Calculation Under Simple Constraints
Assume that x is a simple constraint, and the attribute distribution information related to x already exists in the tuple r of the PGSTATISTIC system catalog (see the Data Distribution Storage section). openGauss calls the clause_selectivity function to convert the tuple _r to the selectivity based on the requirements of x.
The second parameter clause of clause_selectivity is constraint statement x. For different SQL queries, there may be multiple types of clauses for the input clause_selectivity. Table 9 lists the typical types.
Table 9 Simple constraint types
{Var, Const, Param, OpExpr} are basic constraints and {AND, OR, NOT} are SET constraints. Obviously, the constraint {Var, Const, Param} can be considered as a special example of the OpExpr constraint. For example, SELECT * FROM PRODUCT WHERE ISSOLD is equivalent to SELECT * FROM PRODUCT WHERE ISSOLD = TRUE. Due to limitations of space, this section will describe the selectivity calculation based on the OpExpr constraint in detail, and briefly introduces the key logic of the selectivity calculation based on constraints of the SET type.
(1) Selectivity calculation based on the OpExpr constraint
The query statement SELECT * FROM PRODUCT WHERE PRIZE = '100' is used as an example. The clause_selectivity function finds the OpExpr branch based on the clause (PRIZE = '100') type. Then it calls the treat_as_join_clause function to determine whether the clause is a join constraint. If the result is false, the clause is a filter condition (OP). In this case, it calls the restriction_selectivity function to estimate the selectivity of the clause parameter. The code is as follows:
Selectivity clause_selectivity(PlannerInfo *root, Node *clause, int varRelid, JoinType jointype, SpecialJoinInfo *sjinfo) { Selectivity s1 = 0.5;/* default for any unhandled clause type */ RestrictInfo *rinfo = NULL; if (clause == NULL) /* can this still happen? */ return s1; if (IsA(clause, Var))... else if (IsA(clause, Const))... else if (IsA(clause, Param)) // Processing branch of the NOT clause else if (not_clause(clause)) { /* inverse of the selectivity of the underlying clause */ s1 = 1.0 - clause_selectivity(root, (Node *) get_notclausearg((Expr *) clause), varRelid, jointype, sjinfo); } // Processing branch of the AND clause else if (and_clause(clause)) { /* share code with clauselist_selectivity() */ s1 = clauselist_selectivity(root, ((BoolExpr *) clause)->args, varRelid, jointype, sjinfo); } // Processing branch of the OR clause else if (or_clause(clause)) { ListCell *arg; s1 = 0.0; foreach(arg, ((BoolExpr *) clause)->args) { Selectivity s2 = clause_selectivity(root, (Node *) lfirst(arg), varRelid, jointype, sjinfo); s1 = s1 + s2 - s1 * s2; } } // Processing branch of the join or OP clause else if (is_opclause(clause) || IsA(clause, DistinctExpr)) { OpExpr *opclause = (OpExpr *) clause; Oidopno = opclause->opno; // Process the join clause. if (treat_as_join_clause(clause, rinfo, varRelid, sjinfo)) { /* Estimate selectivity for a join clause. */ s1 = join_selectivity(root, opno, opclause->args, opclause->inputcollid, jointype, sjinfo); } //Process the OP clause. else { /* Estimate selectivity for a restriction clause. */ s1 = restriction_selectivity(root, opno, opclause->args, opclause->inputcollid, varRelid); } } ... ... return s1; }The restriction_selectivity function identifies that PRIZE = '100' is an equivalent constraint like Var = Const. It indirectly calls the var_eq_const function through the eqsel function to estimate the selectivity. In this process, the var_eq_const function reads the PRIZE column distribution information in the PG_STATISTIC system catalog and attempts to use the MCV in the information to calculate the selectivity. The get_attstatsslot function is preferentially called to check whether 100 exists in the MCV in the following cases:
Case 1: If yes, the proportion of '100' is directly returned from the MCV as the selectivity.
Case 2: If no, calculate the total proportion sumcommon of high frequency values and return (1.0 – sumcommon – nullfrac)/otherdistinct as the selectivity. nullfrac is the proportion of NULL values, and otherdistinct is the NDV of low frequency values.
Because the constraint added for query is PRIZE < '100', the restrictionselectivity function will call the scalargtsel function based on the operator type and attempt to calculate the selectivity using the information in the PG_STATISTIC system catalog. The values that meet the condition <'100' may exist in the MCV and EH respectively. Therefore, values need to be collected in the two structures respectively. Compared with that in the MCV, the process of collecting the values that meet the conditions in the EH is more complex. Based on the order of keys in the EH, openGauss uses binary search to quickly search for values that meet the conditions, sums up the total proportion of the values, and records the sum as selec_histogram. Note that the EH does not record the frequency of '100' separately. Instead, it combines '100' and adjacent values into a bucket (recorded as bucket _B) and records only the total frequency (Fb) of the values in bucket B. To solve this problem, openGauss assumes that the frequencies of elements in the bucket are the same and uses the following formula:

To estimate the proportion of values that meet the conditions in B. The specific code of this process is implemented in the ineq_histogram_selectivity function. Finally, the selectivity value returned by the restriction_selectivity function is selec = selec_mcv + selec_histogram, where selec_mcv is the percentage of MCVs that meet the conditions.
Selectivity calculation based on constraints of the SET type
For a SET constraint, the clause_selectivity function recursively calculates the selectivity of its basic constraints. The final selectivity is then returned in the manner listed in Table 10 according to the semantics of the SET type.
Table 10 Selectivity of the SET type
By refering to the data distribution storage section, you may find that openGauss does not store the multi-attribute joint distribution. As shown in Table 6-15, openGauss calculates the joint distribution based on the assumption that the values of different columns are independent of each other. In the scenario where columns are not independent, the prediction often has deviations. For example, for the student table, the gender is related to the major. Therefore, the number of students in a computer department cannot be calculated by multiplying the proportion of male students by the number of students in the department. However, independent assumptions can generally lead to accurate results.
(3) Default selectivity parameters
When the data distribution is unknown, the selectivity cannot be estimated by using the conventional method. For example, the ANALYZE operation is not performed on the data table, or the filter condition is an uncertain parameter. To provide a proper reference value for the optimizer, openGauss provides a series of empirical parameters of the selectivity, as shown in Table 11.
Table 11 Selectivity parameters


4. Cost Estimation
Query execution costs are classified into I/O costs and CPU costs. Both costs are positively correlated with the number of tuples processed during the query. Therefore, it is relatively accurate to estimate the total cost of the query plan by using the selectivity. However, due to the differences in hardware environments, the cost model of openGauss outputs only a common indicator for measuring the plan quality, not the execution time. To describe the measurement process, the following describes the I/O and CPU cost estimation methods from the perspective of cost model parameters.
(1) I/O cost estimation
On disks, tuples are organized as data pages. Page access modes include sequential read and random read. Restricted by the performance of storage media, the efficiency of sequential read is much higher than that of random read. For example, when HDDs face a large number of random access requests, the head seek time occupies most of the data read time. In openGauss, the I/O costs in different access modes are as follows:
DEFAULT_SEQ_PAGE_COST 1.0 DEFAULT_RANDOM_PAGE_COST 4.0By default, the ratio of sequential read overheads to random read overheads on data pages is set to 1:4.
The setting is reasonable for HDDs. However, for SSDs with excellent addressing capabilities, this parameter needs to be adjusted based on the actual requirements. In practice, database deployment is complex, and a system may have multiple different storage media at the same time. To enable the cost model to cope with the I/O performance of different storage media, openGauss provides users with a method of setting the unit cost of file I/O.
CREATE TABLESPACE TEST_SPC LOCATION '...' WITH (SEQ_PAGE_COST=2, RANDOM_PAGE_COST=3);According to the I/O cost parameter and the selectivity, the I/O overhead of the candidate plan can be easily estimated. The following uses sequential scan (SeqScan) and index scan (IndexScan) as examples to describe the cost estimation process.
- SeqScan: traverses table data from the beginning to the end. This is a sequential read. Therefore, the I/O cost of SeqScan is DEFAULT_SEQ_PAGE_COST multiplied by the total number of data pages in the table.
- IndexScan: uses indexes to search for table data that meets constraints. This is a random read. Therefore, the I/O cost of IndexScan is x DEFAULT_RANDOM_PAGE_COST.
P (number of data pages that meet the constraint) is positively correlated with R (number of tuples that meet the constraint), and R = Total number of tuples in the table x Selectivity. After openGauss calculates R, it invokes the indexpages_fetched(R, ...) function to estimate _P. This function is implemented in the costsize.c file. For details, see the paper* Index scans using a finite LRU buffer: A validated I/O model* of Mackert L F and Lohman G M.
By observing the cost model, we can find that when the selectivity exceeds a certain threshold, P is relatively large, and the cost of IndexScan is higher than that of SeqScan. Therefore, the efficiency of IndexScan is not always higher than that of SeqScan.
(2) CPU cost estimation
The database consumes CPU resources in the data addressing and data processing phases, for example, tuple projection selection and index search. Obviously, for different operations, the cost of the CPU is different. openGauss divides the CPU cost into tuple processing cost and data operation cost.
① Tuple processing cost: cost of converting a piece of disk data into a tuple. For ordinary table data and index data, the cost parameters are as follows:
#define DEFAULT_CPU_TUPLE_COST 0.01 #define DEFAULT_CPU_INDEX_TUPLE_COST 0.005Among the default parameters, the index cost is lower. This is because index data typically involves fewer columns than table data and requires less CPU resources.
② Data operation cost: cost of projecting a tuple or determining whether a tuple meets the condition based on the constraint expression. The cost parameters are as follows:
#define DEFAULT_CPU_OPERATOR_COST 0.0025Given the above parameters, the estimated CPU cost is proportional to the computation scale of the problem, which depends on the selectivity. This relationship is similar to the relationship between the complexity of the algorithm instance and n. Due to limited space, this section does not provide details.
Physical Path
In the database, paths are represented by the path structure. The path structure is derived from the node structure. The path structure is also a base structure, which is similar to the base class in C++. Each specific path is derived from the path structure. For example, the IndexPath structure used by the index scanning path is derived from the path structure.
typedef struct Path
{
NodeTag type;
NodeTag pathtype; /* Path type, such as T_IndexPath and T_NestPath.*/
RelOptInfo *parent; /* Intermediate result generated after the current path is executed.*/
PathTarget *pathtarget; /* Projection of the path. The expression cost is also saved.*/
/* Pay attention to the expression index.*/
ParamPathInfo *param_info; /* Parameter used during execution. In the executor, subqueries or some special */
/* joins need to obtain the current value of another table in real time.*/
Bool parallel_aware; /* Parallel parameter, which is used to distinguish parallel and non-parallel.*/
bool parallel_safe; /* Parallel parameter, which is determined by the set_rel_consider_parallel function.*/
int parallel_workers; /* Parallel parameter, indicating the number of parallel threads.*/
double rows; /* Estimated amount of data in the intermediate result generated during the execution of the current path.*/
Cost startup_cost; /* Startup cost, that is, the cost from statement execution to obtaining the first result.*/
Cost total_cost; /* Overall execution cost of the current path.*/
List *pathkeys; /* Key value for sorting intermediate results generated in the current path. If the intermediate results are unordered, the value is NULL.*/
} Path;
Dynamic Programming
Currently, openGauss has completed rule-based query rewriting and logical decomposition, and has generated the physical path of each base table. The physical path of the base table is only a small part of the optimizer planning. Now, openGauss will enter another important task of the optimizer, that is, generating the join path. openGauss uses the bottom-up optimization. For the multi-table join path, dynamic programming and genetic algorithm are used. This section mainly introduces dynamic programming. But if there are a large number of tables, genetic algorithm is required. Genetic algorithm can avoid the problem of space expansion during join path search in the case of too many tables. In common scenarios, dynamic programming is used, which is the default optimization method used by the openGauss.
After logical decomposition and optimization, tables in the statement are flattened, that is, the original tree structure is changed to the flattened array structure. The join relationships between tables are also recorded in the SpecialJoinInfo structure in the root directory, which is the basis for dynamic join planning.
1. Dynamic Programming Method
First, the dynamic programming method is applicable to an optimal solution problem including a large quantity of repeated sub-problems. By memorizing the optimal solution to each sub-problem, same sub-problems are solved only once, and a record of solving the previous same sub-problem may be reused next time. As such, it is required that the optimal solutions to these sub-problems can form the optimal solution to the whole problem, that is, they should have the property of the optimal substructure. For statement join optimization, the optimal solution to an entire statement join is the optimal solution to a block of statement join. In a planning process, a local optimal solution cannot be repeatedly calculated, and the local optimal solution calculated last time is directly used.


FIG. 1 Optimal solution to a repeated sub-problem
For example, the join operation of A x B in two join trees in Figure 1 is a repeated sub-problem, because no matter whether the A x B x C x D join path or the A x B x C join path is generated, the A x B join path needs to be generated first. There may be hundreds of join methods for a path generated by multi-table join, that is, when many layers are stacked. The number of repeated sub-problems of these join trees is large. Therefore, the join tree has repeated sub-problems, which can be solved once and used for multiple times. That is, for the join A x B, the optimal solution needs to be generated only once.
The code of the multi-table join dynamic programming algorithm starts from the make_rel_from_joinlist function, as shown in Figure 2.

Figure 2 Multi-table join dynamic programming algorithm
1)make_rel_from_joinlist function
The main entry of the implementation code of dynamic programming starts from the make_rel_from_joinlist function. The input parameter of the make_rel_from_joinlist function is the RangeTableRef linked list after the deconstruct_jointree function is flattened. Each RangeTableRef represents a table. You can search for the RelOptInfo structure of the base table based on the linked list. The found RelOptInfo structure is used to construct a base table RelOptInfo structure at layer 1 of the dynamic programming algorithm, and "accumulation" continues to be performed at layer-1 RelOptInfo structure subsequently. The code is as follows:
// Traverse the joinlist after leveling. The linked list is the linked list of RangeTableRef. foreach(jl, joinlist) { Node *jlnode = (Node *) lfirst(jl); RelOptInfo *thisrel; // In most cases, the RangeTableRef linked list is used. The subscript value (rtindex) stored in the RangeTableRef linked list is used. // Search for the corresponding RelOptInfo structure. if (IsA(jlnode, RangeTblRef)) { int varno = ((RangeTblRef *) jlnode)->rtindex; thisrel = find_base_rel(root, varno); } // Affected by the from_collapse_limit and join_collapse_limit parameters, there are nodes that are not flattened. In this case, the make_rel_from_joinlist function is invoked recursively. else if (IsA(jlnode, List)) thisrel = make_rel_from_joinlist(root, (List *) jlnode); else ereport (......); // The first initial linked list is generated, that is, the linked list of the base table. // This linked list is the basis of the dynamic programming method. initial_rels = lappend(initial_rels, thisrel); }2)standard_join_search function
In the dynamic programming method, a table is added to each layer in the process of accumulating tables. When all tables are added, the final join tree is generated. Therefore, the number of accumulated layers is the number of tables. If there are N tables, data needs to be accumulated for N times. The accumulation process at each layer is described in the join_search_one_level function. This function is mainly used to prepare for the accumulation join, including allocating memory space occupied by RelOptInfos at each layer and reserving some information after RelOptInfos at each layer are accumulated.
Create a "join array", which is similar to a structure of [LIST1, LIST2, LIST3], where a linked list in the array is used to store all RelOptInfo structures of a layer in the dynamic programming method. For example, the first linked list in the array stores linked lists related to all base table paths. The code is as follows:
// Allocate the RelOptInfo linked lists of all layers during accumulation. root->join_rel_level = (List**)palloc0((levels_needed + 1) * sizeof(List*)); // Initialize all layer-1 base table RelOptInfos. root->join_rel_level[1] = initial_rels; After completing the initialization, you can start trying to build RelOptInfo for each layer. The code is as follows: for (lev = 2; lev <= levels_needed; lev++) { ListCell* lc = NULL; // Generate all RelOptInfo structures of the corresponding layer in the join_search_one_level function. join_search_one_level(root, lev); ... }3)join_search_one_level function
The join_search_one_level function is mainly used to generate all RelOptInfos in one layer, as shown in Figure 3. To generate RelOptInfo of the _N_th layer, there are mainly three manners: one is to attempt to generate a left-deep tree and a right-deep tree, one is to attempt to generate a bushy tree, and the other is to attempt to generate a join path of a Cartesian product (commonly referred to as a traversal attempt).

Figure 3 Manners of generating RelOptInfo of the Nth layer
(1) Left-deep tree and right-deep tree
The generation principle of the left-deep tree is the same as that of the right-deep tree, except that the positions of the two RelOptInfos to be joined are exchanged in the make_join_rel function. That is, each RelOptInfo has a chance to be used as an inner table or an outer table. In this way, more joins may be created to help generate the optimal path.
As shown in Figure 4, two RelOptInfos to be selected need to be joined to generate A x B x C, and the left-deep tree is to exchange positions of AxB and C. A x B is used as an inner table to form a left-deep tree, and A x B is used as an outer table to form a right-deep tree.
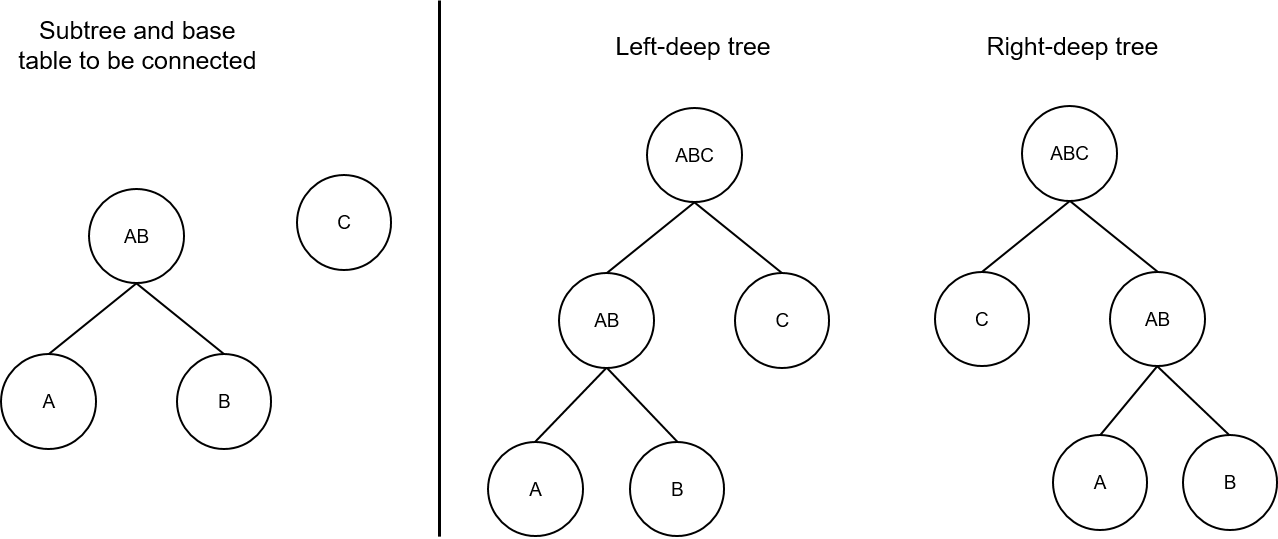
Figure 4 Schematic diagram of a left-deep tree and a right-deep tree
The code is as follows:
// Traverse the upper layer of the current layer, that is, to generate RelOptInfo of layer 4, // try to join RelOptInfo at layer 3 and the base table at layer 1. foreach(r, joinrels[level - 1]) { RelOptInfo *old_rel = (RelOptInfo *) lfirst(r); // If there is a join relationship or join sequence restriction between two RelOptInfos, // a join is preferentially generated for the two RelOptInfos. // The has_join_restriction function may make a misjudgment. However, more refined filtering will be provided in the future. if (old_rel->joininfo != NIL || old_rel->has_eclass_joins || has_join_restriction(root, old_rel)) { ListCell *other_rels; // To generate RelOptInfo of the Nth layer, RelOptInfo of the (N – 1)th layer needs to be joined with the base table set of the first layer. // That is, if the RelOptInfo of layer 2 needs to be generated, the RelOptInfo of layer 1 and the base table set of layer 1 are joined. // Therefore, processing is required when tables at layer 2 are generated from base tables to prevent itself from being joined with itself. if (level == 2) other_rels = lnext(r); else other_rels = list_head(joinrels[1]); // old_rel "may" have join constraints or join sequence restrictions with other tables. // other_rels "may" contain the possible tables. The make_rels_clause_joins function performs accurate judgment. make_rels_by_clause_joins(root, old_rel, other_rels); } else { // Try to generate a join path for tables without join relationships or tables with join sequence restrictions. make_rels_by_clauseless_joins(root, old_rel, list_head(joinrels[1])); } }(2) Bushy tree
To generate RelOptInfo of the N_th layer, the left-deep tree or the right-deep tree joins RelOptInfo of the (N – 1)th layer with the base table of the first layer. Regardless of the left-deep tree or the right-deep tree, in essence, it constructs the current-layer RelOptInfo by referencing the base table RelOptInfo. A bushy tree is generated without using the base table. The bushy tree attempts to randomly join RelOptInfos of all layers. For example, RelOptInfo of the (_N – 2)th layer and that of the second layer are joined, and circumstances with (2,N – 2), (3,N – 3), (4,N – 4), and more may be deduced in sequence. The establishment of a bushy tree must meet two conditions: One is that two RelOptInfos have a related constraint or a restriction on the join sequence, and the other is that two RelOptInfos cannot have an intersection table.
for (k = 2;; k++) { int other_level = level - k; foreach(r, joinrels[k]) { // There are join constraints or join sequence restrictions. if (old_rel->joininfo == NIL && !old_rel->has_eclass_joins && !has_join_restriction(root, old_rel)) continue; ... for_each_cell(r2, other_rels) { RelOptInfo *new_rel = (RelOptInfo *) lfirst(r2); // No intersection is allowed. if (!bms_overlap(old_rel->relids, new_rel->relids)) { // There are related join constraints or restrictions on the join sequence. if (have_relevant_joinclause(root, old_rel, new_rel) || have_join_order_restriction(root, old_rel, new_rel)) { (void) make_join_rel(root, old_rel, new_rel); } } } } }(3) Cartesian product
After trying the left-deep tree, right-deep tree, and bushy tree, if no legal join is generated, a final attempt needs to be made on RelOptInfos of layer N – 1 and layer 1. That is, an attempt is made to join each RelOptInfo at the (N – 1)th layer with RelOptInfo at the first layer.
2. Path Generation
We have learned the dynamic programming method used in path generation, and how to generate RelOptInfo for the current layer during the accumulation process in the previous section. For generating RelOptInfo of the current layer, several problems may be faced: one is to determine whether two RelOptInfos can be joined, and the other is to generate a physical join path. Currently, a physical join path mainly has three implementations: NestLoopJoin, HashJoin, and MergeJoin. A process of establishing the join path is a process of continuously attempting to generate the three paths.
Perform check
In the dynamic programming method, each RelOptInfo of the N – 1 layer and each RelOptInfo of the first layer need to be joined, and then the RelOptInfo of the new join is stored in the current N_th layer. The time complexity of the algorithm is about O (M x N). If there are a relatively large quantity of RelOptInfos at both the (_N – 1)th layer and the first layer, the search space expands greatly. However, some RelOptInfos can be avoided during join. This is also the purpose of timely check. Detecting and skipping the join between two RelOptInfos in advance can save unnecessary overheads and improve the optimization efficiency of the optimizer.
(1) Preliminary check
The following conditions are the main factors to be measured in the preliminary check:
The value of joininfo in RelOptinfo is not NULL. This indicates that the RelOptInfo has related constraints with other RelOptInfos. That is, the current RelOptInfo may be associated with other tables.
The value of has_eclass_joins in RelOptInfo is true, indicating that the current RelOptInfo and other RelOptInfos may have equivalent join conditions in the equivalence class record.
The return value of the has_join_restriction function is true, indicating that the join sequence between the current RelOptInfo and other RelOptInfos is limited.
The preliminary check is to use the RelOptInfo information to determine the possibility, that is, to check whether there are join conditions and join sequence constraints.
static bool has_join_restriction(PlannerInfo* root, RelOptInfo* rel) { ListCell* l = NULL; // If the current RelOptInfo involves Lateral semantics, there must be join sequence constraints. foreach(l, root->lateral_info_list) { LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l); if (bms_is_member(ljinfo->lateral_rhs, rel->relids) || bms_overlap(ljinfo->lateral_lhs, rel->relids)) return true; } // Process only the conditions except the inner join. foreach (l, root->join_info_list) { SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l); // Skip the full-join check. Other mechanisms are used to ensure the join sequence. if (sjinfo->jointype == JOIN_FULL) continue; // If the SpecialJoinInfo has been included in the RelOptInfo, skip this step. if (bms_is_subset(sjinfo->min_lefthand, rel->relids) && bms_is_subset(sjinfo->min_righthand, rel->relids)) continue; //If the relids and min_lefthand or min_righthand variables of the RelOptInfo structure overlap, there may be constraints on the join sequence. if (bms_overlap(sjinfo->min_lefthand, rel->relids) || bms_overlap(sjinfo->min_righthand, rel->relids)) return true; } return false; }
(2) Precise check
After the preliminary check, if it is determined that there is no join condition or join sequence constraint on the RelOptInfos on both sides, the make_rels_by_clauseless_joins function is entered, and all possible paths in the RelOptInfo are joined with the RelOptInfo at layer 1. If the current RelOptInfo may have join constraints or join sequence restrictions, the make_rel_by_clause_joins function is invoked to further check the current RelOptInfo and other RelOptInfo at layer 1 to determine whether the join can be performed.
The have_join_order_restriction function determines whether there are join sequence restrictions on two RelOptInfos from the following two aspects: One is to determine whether the two RelOptInfos have a Lateral semantic sequence restriction, and the other is to determine whether min_lefthand and min_righthand in SpecialJoinInfo have a join sequence restriction on the two RelOptInfos.
The analysis of the have_join_order_restriction source code is as follows:
bool have_join_order_restriction(PlannerInfo* root, RelOptInfo* rel1, RelOptInfo* rel2) { bool result = false; ListCell* l = NULL; // If the dependency relationship with Lateral semantics exists, the join sequence must be restricted. foreach(l, root->lateral_info_list) { LateralJoinInfo *ljinfo = (LateralJoinInfo *) lfirst(l); if (bms_is_member(ljinfo->lateral_rhs, rel2->relids) && bms_overlap(ljinfo->lateral_lhs, rel1->relids)) return true; if (bms_is_member(ljinfo->lateral_rhs, rel1->relids) && bms_overlap(ljinfo->lateral_lhs, rel2->relids)) return true; } // Traverse all SpecialJoinInfo in the root directory and check whether the two RelOptInfos have join constraints. foreach (l, root->join_info_list) { SpecialJoinInfo* sjinfo = (SpecialJoinInfo*)lfirst(l); if (sjinfo->jointype == JOIN_FULL) continue; // The minimum set is a subset of the two tables. The two tables must be joined in the specified sequence. if (bms_is_subset(sjinfo->min_lefthand, rel1->relids) && bms_is_subset(sjinfo->min_righthand, rel2->relids)) { result = true; break; } // Conversely, the minimum set is a subset of the two tables. The two tables must be joined in the specified sequence. if (bms_is_subset(sjinfo->min_lefthand, rel2->relids) && bms_is_subset(sjinfo->min_righthand, rel1->relids)) { result = true; break; } // If both tables have intersection with one end of the minimum set, the two tables should be joined at the end. // So let them join first. if (bms_overlap(sjinfo->min_righthand, rel1->relids) && bms_overlap(sjinfo->min_righthand, rel2->relids)) { result = true; break; } // The reverse is the same as above. if (bms_overlap(sjinfo->min_lefthand, rel1->relids) && bms_overlap(sjinfo->min_lefthand, rel2->relids)) { result = true; break; } } // If the two tables have corresponding join relationships with other tables, // you can join them with the tables with join relationships first. if (result) { if (has_legal_joinclause(root, rel1) || has_legal_joinclause(root, rel2)) result = false; } return result; }(3) Legal join
As RelOptInfo causes search space expansion, if the legal join check is performed on the two RelOptInfo structures, the search time is too long. This is why the preliminary check and accurate check need to be performed in advance. The search time can be reduced to achieve the pruning effect.
For legal joins, the main code is in join_is_legal, which is used to determine whether two RelOptInfo structures can be joined to generate a physical path. The input parameters are the two RelOpInfo structures. The logical join between two RelOptInfo structures to be selected may be InnerJoin, LeftJoin, or SemiJoin, or no legal logical join exists. In this case, you need to determine the join in two steps.
Step 1: Traverse SpecialJoinInfo in the join_info_list linked list in the root directory to check whether a legal SpecialJoinInfo can be found. A corresponding SpecialJoinInfo is generated for each logical join relationship except InnerJoin. In addition, the legal join sequence is recorded in SpecialJoinInfo.
Step 2: Check the Lateral relationship in RelOptInfo and check whether the found SpecialJoinInfo meets the join sequence requirement specified by the Lateral semantics.
Create a join path
So far, two RelOptInfo structures that meet the condition have been filtered out. The next step is to establish a physical join relationship for paths in the two RelOptInfo structures. Common physical join paths include NestLoop, MergeJoin, and HashJoin, which are implemented by using the sort_inner_and_outer, match_unsorted_outer, and hash_inner_and_outer functions.
For example, the sort_inner_and_outer function is used to generate the MergeJoin path. It is assumed that the paths of the inner and outer tables are unordered. Therefore, the paths must be sorted explicitly. The path with the lowest total cost is selected for the inner and outer tables. The matvh_unsorted_outer function indicates that the outer table is sorted. In this case, you only need to sort the inner table to generate the MergeJoin path, NestLoop, or parameterized path. The final choice is to set up a HashJoin path to join the two tables, that is, to set up a hash table.
To facilitate the creation of MergeJoin, constraints need to be processed first. Therefore, the constraints applicable to MergeJoin are filtered out (select_mergejoin_clauses function). In this way, the Mergejoinable join constraint can be used in both the sort_inner_and_outer and match_unsorted_outer functions. The code is as follows:
// Extract the conditions for MergeJoin. foreach (l, restrictlist) { RestrictInfo* restrictinfo = (RestrictInfo*)lfirst(l); // If the current join is an outer join and is a filter condition, ignore it. if (isouterjoin && restrictinfo->is_pushed_down) continue; // Preliminarily determine whether the join constraint can be used for MergeJoin. // restrictinfo->can_join and restrictinfo->mergeopfamilies are generated in distribute_qual_to_rels. if (!restrictinfo->can_join || restrictinfo->mergeopfamilies == NIL) { // Ignore FULL JOIN ON FALSE. if (!restrictinfo->clause || !IsA(restrictinfo->clause, Const)) have_nonmergeable_joinclause = true; continue; /* not mergejoinable */ } // Check whether the constraint is in the form of outer op inner or inner op outer. if (!clause_sides_match_join(restrictinfo, outerrel, innerrel)) { have_nonmergeable_joinclause = true; continue; /* no good for these input relations */ } // Update and use the final equivalence class. // Normalize pathkeys so that constraints can match pathkeys. update_mergeclause_eclasses(root, restrictinfo); if (EC_MUST_BE_REDUNDANT(restrictinfo->left_ec) || EC_MUST_BE_REDUNDANT(restrictinfo->right_ec)) { have_nonmergeable_joinclause = true; continue; /* can't handle redundant eclasses */ } result_list = lappend(result_list, restrictinfo); }(1) sort_inner_and_outer function
The sort_inner_and_outer function is mainly used to generate a MergeJoin path. It needs to explicitly sort the two child RelOptInfo structures, and only the cheapest_total_path function in the child RelOptInfo needs to be considered. Generate pathkeys by using the join constraint of MergeJoinable (which can be used to generate Merge Join), and then continuously adjust the sequence of pathkeys in pathkeys to obtain different pathkeys. Then, the innerkeys of the inner table and outerkeys of the outer table are determined based on the pathkeys in different sequences. The code is as follows:
// Try to join and traverse each path in the outer table and inner table. foreach (lc1, outerrel->cheapest_total_path) { Path* outer_path_orig = (Path*)lfirst(lc1); Path* outer_path = NULL; j = 0; foreach (lc2, innerrel->cheapest_total_path) { Path* inner_path = (Path*)lfirst(lc2); outer_path = outer_path_orig; // The parameterized path cannot be used to generate the MergeJoin path. if (PATH_PARAM_BY_REL(outer_path, innerrel) || PATH_PARAM_BY_REL(inner_path, outerrel)) return; // The lowest-cost path of the outer table and inner table must be met. if (outer_path != linitial(outerrel->cheapest_total_path) && inner_path != linitial(innerrel->cheapest_total_path)) { if (!join_used[(i - 1) * num_inner + j - 1]) { j++; continue; } } // Generate a unique path. jointype = save_jointype; if (jointype == JOIN_UNIQUE_OUTER) { outer_path = (Path*)create_unique_path(root, outerrel, outer_path, sjinfo); jointype = JOIN_INNER; } else if (jointype == JOIN_UNIQUE_INNER) { inner_path = (Path*)create_unique_path(root, innerrel, inner_path, sjinfo); jointype = JOIN_INNER; } // Determine the pathkeys set that can be generated by the MergeJoin path based on the extracted conditions. all_pathkeys = select_outer_pathkeys_for_merge(root, mergeclause_list, joinrel); // Process each pathkey in the preceding pathkeys and try to generate a MergeJoin path. foreach (l, all_pathkeys) { ... // Generate the pathkey of the inner table. innerkeys = make_inner_pathkeys_for_merge(root, cur_mergeclauses, outerkeys); // Generate the pathkey of the outer table. merge_pathkeys = build_join_pathkeys(root, joinrel, jointype, outerkeys); // Generate the MergeJoin path based on the pathkey and inner and outer table paths. try_mergejoin_path(root, ......, innerkeys); } j++; } i++; }(2) match_unsorted_outer function
The overall code roadmap of the match_unsorted_outer function is similar to that of the sort_inner_and_outer function, except that the sort_inner_and_outer function infers the pathkeys of the inner and outer tables based on conditions. In the match_unsorted_outer function, the outer table path is assumed to be ordered. It sorts the join constraints based on the pathkey of the outer table. That is, the pathkeys of the outer table can be used as outerkeys, so as to check which join constraint matches the current pathkeys, filter the matched join constraint, and generate the innerkeys that needs to be displayed and sorted based on the matched join constraint.
(3) hash_inner_and_outer function
The hash_inner_and_outer function is used to create a HashJoin path. The distribute_restrictinfo_to_rels function has determined whether a constraint is applicable to HashJoin. To create a hash table, HashJoin can be used only when at least one join constraint applicable to HashJoin exists. Otherwise, the hash table cannot be created.
Filter paths
So far, the physical join paths Hashjoin, NestLoop, and MergeJoin are generated. You need to determine whether a path is worth storage according to the cost calculated during the generation process, because many paths are generated in the path join phase. In addition, some obviously poor paths are generated. In this case, filtering can help you perform a basic check and save the time for generating the plan. Taking a long time to generate a plan is unacceptable, even if it is a "good" execution plan.
add_path is the main function for filtering paths. The code is as follows:
switch (costcmp) { case COSTS_EQUAL: outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path), PATH_REQ_OUTER(old_path)); if (keyscmp == PATHKEYS_BETTER1) { if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) && new_path->rows <= old_path->rows) // The cost of the new path is similar to that of the old path, while the pathkeys is longer and fewer parameters are required. // The number of rows in the result set is small. Therefore, the new path is accepted and the old path is discarded. remove_old = true; /* new dominates old */ } else if (keyscmp == PATHKEYS_BETTER2) { if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) && new_path->rows >= old_path->rows) // The cost of the new path is similar to that of the old path, while the pathkeys is shorter and more parameters are required. // If the result set contains more rows, the new path is not accepted and the old path is retained. accept_new = false; /* old dominates new */ } else { if (outercmp == BMS_EQUAL) { // The cost, pathkeys, and path parameters of the new and old paths are the same or similar. // If the number of rows returned by the new path is small, the new path is accepted and the old path is discarded. if (new_path->rows < old_path->rows) remove_old = true; /* new dominates old */ // If the number of rows returned by the new path is large, the new path is not accepted and the old path is retained. else if (new_path->rows > old_path->rows) accept_new = false; /* old dominates new */ // The cost, pathkeys, path parameters, and number of rows in the result sets are similar. // The range for determining the cost is strictly specified. If the new path is good, the new path is used and the old path is discarded. else { small_fuzzy_factor_is_used = true; if (compare_path_costs_fuzzily(new_path, old_path, SMALL_FUZZY_FACTOR) == COSTS_BETTER1) remove_old = true; /* new dominates old */ else accept_new = false; /* old equals or * dominates new */ } // If the cost and pathkeys are similar, compare the number of rows and parameters. If the number of rows and parameters of the new path is better than those of the old path, discard the old path; if the number of rows and parameters of the old path is better than those of the new path, discard the new path. } else if (outercmp == BMS_SUBSET1 && new_path->rows <= old_path->rows) remove_old = true; /* new dominates old */ else if (outercmp == BMS_SUBSET2 && new_path->rows >= old_path->rows) accept_new = false; /* old dominates new */ /* else different parameterizations, keep both */ } break; case COSTS_BETTER1: // Based on all the comparison results of the new and old paths, it is determined that the new path is better than or equal to the old path. // Therefore, the new path is accepted and the old path is discarded. if (keyscmp != PATHKEYS_BETTER2) { outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path), PATH_REQ_OUTER(old_path)); if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET1) && new_path->rows <= old_path->rows) remove_old = true; /* new dominates old */ } break; case COSTS_BETTER2: // Based on all the comparison results of the new and old paths, it is determined that the old path is better than the old path. //The new path is not accepted and the old path is retained. if (keyscmp != PATHKEYS_BETTER1) { outercmp = bms_subset_compare(PATH_REQ_OUTER(new_path), PATH_REQ_OUTER(old_path)); if ((outercmp == BMS_EQUAL || outercmp == BMS_SUBSET2) && new_path->rows >= old_path->rows) accept_new = false; /* old dominates new */ } break; default: /* * can't get here, but keep this case to keep compiler * quiet */ break; }
Genetic Algorithm
As a kind of evolutionary algorithm, the genetic algorithm draws on natural selection and genetic mechanism in the Darwinian theory of biological evolution. The optimal individual is generated by simulating the evolution process of natural selection and survival of the fittest.
After a specific quantity of original individuals are generated, a new chromosome may be generated by means of gene arrangement and combination, and then a next-generation chromosome is obtained by means of chromosome hybridization and mutation. To select an excellent chromosome, a fitness function needs to be established to calculate a fitness value, so as to eliminate chromosomes with low fitness. In this way, the best individual is gradually evolved through constant inheritance and mutation among individuals. The individual is the solution of the problem by substituting this process into the solution. By genetic algorithm, the solution of the problem can converge to the optimal solution through this kind of intergenerational inheritance.
Different from a method in which dynamic programming resolves a problem into several independent sub-problems, the genetic algorithm is a selection process. The genetic algorithm enlarges a solution space by using a method of constructing a new chromosome by means of chromosome hybridization, and performs screening in the solution space at any time by using a fitness function, to recommend a good gene and eliminate bad genes. As a result, the solution obtained by genetic algorithm is not necessarily the global optimal solution like dynamic programming, but it can be close to the global optimal solution as much as possible by improving hybridization and mutation.
Thanks to the efficiency advantage in multi-table join, genetic algorithm is a useful supplement to the dynamic programming method in openGauss database. The genetic algorithm is used only when the Enable_geqo parameter is enabled and the number of RelOptInfo structures to be joined exceeds Geqo_threshold (12 by default).
The genetic algorithm is implemented in the following five steps:
(1) Pool initialization: A gene is encoded, and a plurality of chromosomes is generated by randomly arranging and combining the genes. These chromosomes form a new pool. In addition, fitness of the chromosome is calculated in the chromosome generation process.
(2) Chromosome selection: A chromosome used for crossover and mutation is selected through random selection (actually, a probability-based random number generation algorithm is used, so that an excellent chromosome can be selected).
(3) Crossover: Chromosomes are crossed over, to generate a new chromosome and add the new chromosome to the pool.
(4) Mutation: A mutation operation is performed on chromosomes, to generate a new chromosome and add the new chromosome to the pool.
(5) Fitness calculation: Eliminates bad chromosomes.
For example, if the genetic algorithm is used to resolve a travelling salesman problem (TSP), cities may be used as genes, a path traveling through each city is used as a chromosome, a total length of the paths is used as fitness, and the fitness function is responsible for screening out a relatively long path and retaining a relatively short path. The algorithm procedure is as follows:
(1) Pool initialization: Cities are numbered, and the cities are arranged and grouped according to the numbers, to generate multiple new paths (chromosomes). Then, an overall path length (fitness) is calculated according to a distance between the cities, and the multiple new paths form a pool.
(2) Chromosome selection: Two paths are selected for crossover (it should be noted that a city cannot repeatedly appear in a new chromosome generated through crossover), and a path length is calculated for a new path generated through the crossover operation.
(3) Mutation: A chromosome is randomly selected for mutation (a common method is to exchange locations of cities in a path), and a path length is calculated for a new path obtained after the mutation operation.
(4) Fitness calculation: All paths in the pool are sorted in ascending order based on the path length, and paths ranked at the bottom are eliminated.
The genetic algorithm of the openGauss database simulates the method of solving the TSP. RelOptInfo is used as a gene, the finally generated join tree is used as a chromosome, the total cost of the join tree is used as fitness, and the fitness function is used for filtering based on the cost of the path; but the join path search in the openGauss database is slightly different from the path search for the TSP. For the TSP, the paths have no connection problems. The two cities are connected and the distance between any two cities can be calculated. Due to the restriction of the join constraints in the database, the two tables cannot be joined, or the join tree cannot be generated. In addition, it should be noted that the implementation of genetic algorithm in the openGauss database is slightly different from that of a common genetic algorithm, and the genetic algorithm in the openGauss database does not have a mutation process, and generates a new chromosome only by means of crossover.
The general entry of genetic algorithm in the openGauss database is the geqo function. The input parameters are root (querying the optimized context information), number_of_rels (number of RelOptInfo structures to be joined), and initial_rels (all base tables).
File Directory Structure
As a relatively independent optimizer module, genetic algorithm has its own file directory structure, as shown in Table 6-17.
Table 6-17 Optimizer file directory structure
These files are stored in src/gausskernel/optimizer/gepo as modules of the optimizer genetic algorithm. We will interpret the code in these files in later sections.
Pool Initialization
Before using the genetic algorithm, you can use the value of Gepo_threshold to adjust the triggering condition. To facilitate code interpretation, the threshold condition is reduced to 4 (that is, the genetic algorithm is used when the number of RelOptInfo structures or base tables is 4). In the following code interpretation process, four tables t1, t2, t3, and t4 are used as examples for description.
As a gene of the genetic algorithm, RelOptInfo needs to be encoded first. The openGauss database uses a real number encoding manner, that is, {1,2,3,4} is used to represent four tables t1, t2, t3, and t4, respectively.
Then, the size of a pool is obtained by using the gimme_pool_size function. The size of the pool is affected by two parameters: Geqo_pool_size and Geqo_effort. The pool is represented by using a Pool structure, and the chromosome is represented by using a Chromosome structure. The code is as follows:
/* Chromosome structure*/
typedef struct Chromosome {
/* string is an integer array, which represents a sorting mode of genes and corresponds to a join tree.*/
/* For example, {1,2,3,4} corresponds to t1 JOIN t2 JOIN t3 JOIN t4. */
/* For example, {2,3,1,4} corresponds to t2 JOIN t3 JOIN t1 JOIN t4. */
Gene* string;
Cost worth; /* Fitness of a chromosome, which is actually a path cost. */
} Chromosome;
/* Pool structure */
typedef struct Pool {
Chromosome *data; /* Chromosome array. Each tuple in the array is a join tree.*/
int size; /* Number of chromosomes, that is, number of join trees in data, generated by gimme_pool_size.*/
int string_length; /* A quantity of genes in each chromosome is the same as a quantity of genes in the base table.*/
} Pool;
In addition, a quantity of times of chromosome crossover is obtained by using the gimme_number_generations function. A larger quantity of times of chromosome crossover indicates that more new chromosomes are generated, and a better solution is more likely to be found. However, the larger quantity of times of chromosome crossover also affects performance. You can adjust the quantity of times of crossover by setting the Geqo_generations parameter.
The variables in the structure are as follows:
(1) A quantity (Pool.size) of chromosomes that are determined by using gimme_pool_size.
(2) A quantity (Pool.string_length) of genes in each chromosome, which is the same as the quantity of base tables.
Then, a chromosome may be generated. The chromosome is generated by using a Fisher-Yates shuffle algorithm, and finally a quantity (Pool.size) of chromosomes are generated. The algorithm is implemented as follows:
/* Initialize the gene sequence to {1,2,3,4}.*/
for (i = 0; i < num_gene; i++)
tmp[i] = (Gene)(i + 1);
remainder = num_gene - 1; /* Define the number of remaining genes.*/
/* Implement the shuffle method to randomly select genes for multiple times as a part of gene encoding.*/
for (i = 0; i < num_gene; i++) {
/* choose value between 0 and remainder inclusive */
next = geqo_randint(root, remainder, 0);
/* output that element of the tmp array */
tour[i] = tmp[next]; /* Gene encoding*/
/* and delete it */
tmp[next] = tmp[remainder]; /* Update the remaining gene sequence.*/
remainder--;
}
Table 6-18 describes the process of generating a chromosome. It is assumed that four random results are {1, 1, 1, 0}.
Table 6-18 Process of generating a chromosome
After a chromosome is randomly generated for a plurality of times, a pool is obtained. It is assumed that there are four chromosomes in total in the pool, and a structure of the pool is described by using a diagram, as shown in Figure 6-13.
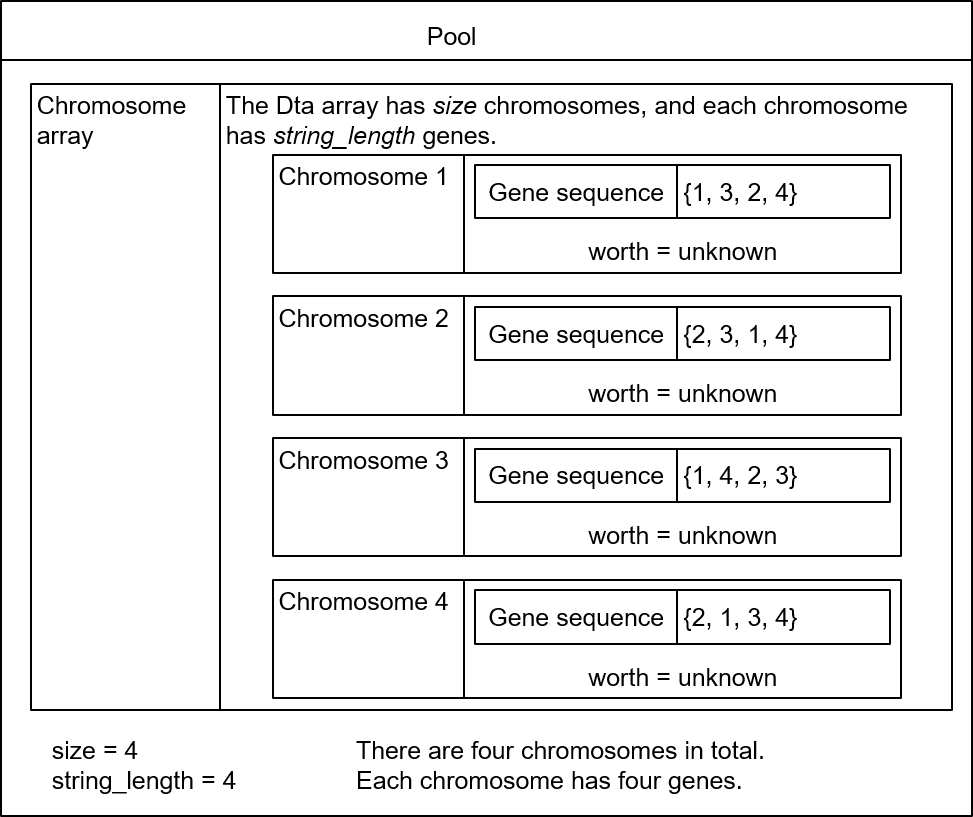
Figure 6-13 Chromosome structure
Then, fitness (worth) is calculated for each chromosome. A process of calculating fitness is actually a process of generating a join tree according to the gene encoding sequence of the chromosome and calculating the cost of the join tree.
In the openGauss database, each chromosome uses a left-deep tree by default. Therefore, after gene encoding of each chromosome is determined, a join tree of the chromosome is determined accordingly. For example, for a chromosome {2, 4, 3, 1}, the corresponding join tree is ((t2, t4), t3), t1), as shown in Figure 6-14.
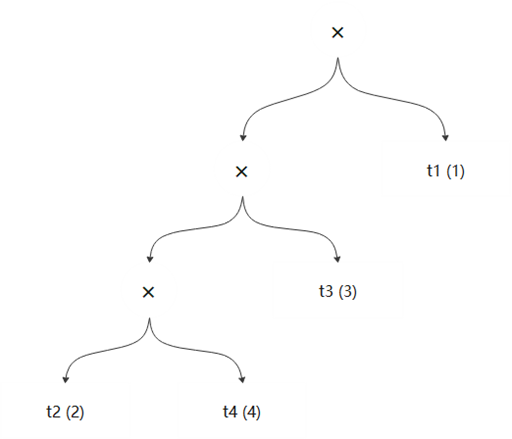
Figure 6-14 Chromosome join tree
The openGauss database generates fitness by using the geqo_eval function. The geqo_eval function first generates a join tree based on gene encoding of a chromosome, and then calculates the cost of the join tree.
The genetic algorithm uses the gimme_tree function to generate a join tree. The merge_clump function is recursively called in the function. The merge_clump function joins tables as many as possible, generates a join subtree, and records the number of nodes in each join subtree. Then, the join subtree is recorded in the clumps linked list in descending order of the number of nodes. The code is as follows:
/* Traverse all tables cyclically and join tables as many as possible.*/
For (rel_count = 0; rel_count < num_gene; rel_count++) {
int cur_rel_index;
RelOptInfo* cur_rel = NULL;
Clump* *cur_clump = NULL;
/* tour represents a chromosome. Here, a gene in the chromosome is obtained, that is, a base table.*/
cur_rel_index = (int) tour[rel_count];
cur_rel = (RelOptInfo *) list_nth(private->initial_rels, cur_rel_index - 1);
/* Generate a clump for the base table. size=1 indicates that there is only one base table in the current clump.*/
cur_clump = (Clump*)palloc(sizeof(Clump));
cur_clump->joinrel = cur_rel;
cur_clump->size = 1;
/* Attempt to join, perform recursive operations, and record the clumps to the clumps linked list.*/
clumps = merge_clump(root, clumps, cur_clump, false);
}
The previously generated chromosome {2, 4, 3, 1} is used as an example, assuming that:
(1) 2 and 4 cannot be joined.
(2) 4 and 3 can be joined.
(3) 2 and 1 can be joined.
Table 6-19 describes the process of generating a join tree under these conditions.
Table 6-19 Join tree generation process
According to the steps in the example, the process of the merge_clumps function is to continuously attempt to generate a larger clump.
/* If a join can be generated, try to generate a join with more nodes through recursion.*/
if (joinrel != NULL) {
...
/* Generate a new join node and increase the number of joined nodes.*/
old_clump->size += new_clump->size;
pfree_ext(new_clump);
/* Delete the joined nodes from the clumps join table.*/
clumps = list_delete_cell(clumps, lc, prev);
/* Use clumps and the newly generated join node (old_clump) as parameters to continue to generate joins.*/
return merge_clump(root, clumps, old_clump, force);
}
According to the example in the preceding table, the clumps linked list contains two nodes, which are two join subtrees. After force is set to true, the system attempts to join the two nodes again.
/* If there are multiple nodes in clumps, it indicates that the join tree is not generated successfully.*/
if (list_length(clumps) > 1) {
...
foreach(lc, clumps) {
Clump* clump = (Clump*)lfirst(lc);
/* Set the force parameter to true and try to join unconditionally.*/
fclumps = merge_clump(root, fclumps, clump, true);
}
clumps = fclumps;
}
3. Operator Selection
After a pool is generated, intergenerational genetic optimization can be performed. Two chromosomes are randomly selected from the pool to perform a crossover operation. In this way, a new chromosome can be generated.
As chromosomes in the pool are already sorted according to fitness, a chromosome with lower fitness (lower cost) is better. It is expected that a better chromosome is inherited. Therefore, a chromosome with lower fitness is preferred when a father chromosome and a mother chromosome are selected. The concept of bias is involved in the selection process. It is a fixed value in the operator. The value of bias can be adjusted through the parameter Geqo_selection_bias (by default, it is 2.0).
/* A father chromosome and a mother chromosome are selected by using the linear_rand function.*/
first = linear_rand(root, pool->size, bias);
second = linear_rand(root, pool->size, bias);
To generate a random number (x) based on a certain probability distribution, you need to know the probability distribution function or probability density function (PDF) first. The PDF  used by the openGauss database is as follows:
used by the openGauss database is as follows:

The following cumulative distribution function (CDF) is obtained by using the PDF:

Then, a random number that conforms to the probability distribution can be obtained by using the PDF and the inverse function method.
Function:

Inverse function:

This is consistent with the implementation of the linear_rand function in the source code.

The code of probability-based random number generation algorithm is extracted for calculation and verification, and the characteristics of random number generation are analyzed. It is assumed that bias is 2.0, and then the PDF is used to calculate the theoretical probability value of each interval for analysis. For example, for a range from 0.6 to 0.7, the theoretical probability is calculated as follows:

Figure 6-15 shows the theoretical probability values in each range.
Figure 6-15 Theoretical probability value of random number generation
It can be learned from Figure 6-15 that theoretical probability values in all ranges decrease sequentially. In other words, when a parent chromosome is selected, a chromosome with lower fitness (lower cost) is more likely to be selected.
4. Crossover Operator
After the parent chromosomes are selected by using the selection operator, a crossover operation may be performed on the selected parent chromosomes, to generate a new child chromosome.
The openGauss provides a plurality of crossover methods, including edge combination crossover, partially matched crossover, cycle crossover, position crossover, and order crossover. In the process of source code analysis, the position crossover method is taken as an example for illustration.
It is assumed that the gene code of the selected father chromosome is {1, 3, 2, 4} with a fitness of 100, and the gene code of the selected mother chromosome is {2, 3, 1, 4} with a fitness of 200. When a child chromosome is not generated and is in an uninitialized state, the statuses of these chromosomes are shown in Figure 6-16.

Figure 6-16 Chromosome status
A random number num_positions needs to be generated for the crossover operation. The position of the random number is in a range between 1/3 and 2/3 of a total quantity of genes. The random number represents a quantity of father chromosome genes that need to be inherited to a child chromosome according to the position. The code is as follows:
/* num_positions determines the number of genes inherited from the father chromosome to the child chromosome.*/
num_positions = geqo_randint(root, 2 * num_gene / 3, num_gene / 3);
/* Select a random position.*/
for (i = 0; i < num_positions; i++)
{
/* A position is randomly generated, and genes at the position of the father chromosome are inherited to the child chromosome.*/
pos = geqo_randint(root, num_gene - 1, 0);
offspring[pos] = tour1[pos];
/* Mark that the genes at this position have been used. The mother chromosome cannot inherit the same genes to the child chromosome.*/
city_table[(int) tour1[pos]].used = 1;
}
It is assumed that the father chromosome needs to inherit two genes to the child chromosome, to respectively transmit gene 1 and gene 2. In this case, the status of the child chromosome is shown in Figure 6-17.

Figure 6-17 Current chromosome status
Currently, the child chromosome already has two genes: 3 and 2. After the mother chromosome excludes the two genes, there are still two genes: 1 and 4. The two genes are written into the child chromosome according to the sequence in the mother chromosome, and a new child chromosome is generated, as shown in Figure 6-18.

Figure 6-18 New chromosome status
5. Fitness Calculation
After the newly generated child chromosome is obtained, you can calculate fitness by using the geqo_eval function. Then, add the chromosome to the pool by using the spread_chromo function.
/* Fitness analysis */
kid->worth = geqo_eval(root, kid->string, pool->string_length);
/* Diffusion of the chromosome based on fitness*/
spread_chromo(root, kid, pool);
Because chromosomes in the pool should always be in an ordered state, the spread_chromo function may traverse the pool by using the dichotomy to compare fitness of the chromosomes in the pool and fitness of the new chromosome, and search for a position for inserting the new chromosome according to the fitness. The chromosome behind it automatically moves back by one position, and the last chromosome is eliminated. If the fitness of the new chromosome is the highest, the chromosome is eliminated directly. The code is as follows:
/* Use the dichotomy to traverse chromosomes in the pool.*/
top = 0;
mid = pool->size / 2;
bot = pool->size - 1;
index = -1;
/* Chromosome screening*/
while (index == -1) {
/* Moving is required in the following four cases.*/
if (chromo->worth <= pool->data[top].worth) {
index = top;
} else if (chromo->worth - pool->data[mid].worth == 0) {
index = mid;
} else if (chromo->worth - pool->data[bot].worth == 0) {
index = bot;
} else if (bot - top <= 1) {
index = bot;
} else if (chromo->worth < pool->data[mid].worth) {
/*
* The following two cases are handled separately because no new position is found.
*/
bot = mid;
mid = top + ((bot - top) / 2);
} else { /* (chromo->worth > pool->data[mid].worth) */
top = mid;
mid = top + ((bot - top) / 2);
}
}
The genetic algorithm continuously generates a new chromosome for a pool by selecting an excellent chromosome and performing intergenerational crossover for a plurality of times, and the chromosome is repeatedly generated, so as to push a solution of the algorithm to approach from local optimal to global optimal.
Summary
This chapter describes the implementation process of the SQL engine, including SQL parsing, query rewriting, and query optimization. The SQL engine involves a large amount of code, featuring high code coupling and complex implementation logic. For better understanding, you are advised to master the overall code process and key structures, and summarize them in practice.