Using DataChecker to Ensure Data Accuracy After Migration
Using DataChecker to Ensure Data Accuracy After Migration
We have introduced several tools for migrating data from Oracle or MySQL to openGauss. Now, we can use the DataChecker tool to ensure data accuracy after migration.
1 Introduction to DataChecker
DataChecker is a tool written in Java for checking data consistency between two databases. Some of its architecture and implementation are based on Alibaba's open-source data migration tool yugong.
Code repository: https://gitee.com/opengauss/openGauss-tools-datachecker
1.1 Application Scenario
Generally, DataChecker is used to verify data accuracy after the data is migrated. After migrating a large amount of data from one database to another, you need to check whether the migrated data is accurate and complete. In this case, you can use DataChecker to check whether the data in the two databases is consistent.
1.2 Implementation Principles
The architecture of DataChecker consists of two parts: Extractor and Applier.
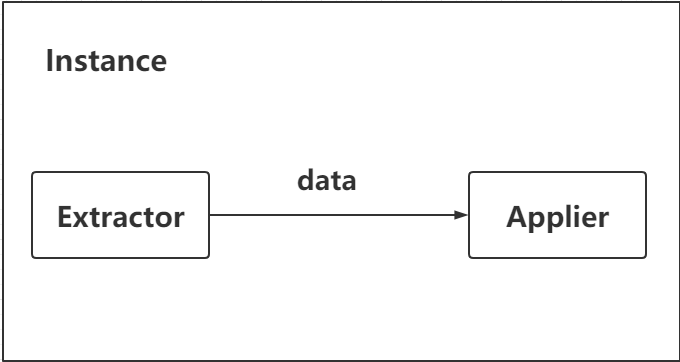
Extractor is used to extract data from the source database. Data is extracted in batches based on the sequence of the data in the source table.
Applier is used to locate the data extracted by Extractor in the target database, compare the columns one by one, and return the result.
2 Usage Guide
2.1 Environment Requirements
Operating System
DataChecker is developed based on Java with bat and shell scripts. It supports both Windows and Linux.
JDK 1.6.25 or later is recommended.
Database
The source database supports MySQL and will support Oracle in the future.
The target database supports only openGauss.
2.2 Downloading DataChecker
You can download the source code and compiled package at https://gitee.com/opengauss/openGauss-tools-datachecker.
Self-compilation:
git clone git@gitee.com:opengauss/openGauss-tools-datachecker.git cd openGauss-tools-datachecker mvn clean install -Dmaven.test.skip -Denv=releaseIf you do not want to compile the binary package by yourself, you can obtain the complied binary package DataChecker-1.0.0-SNAPSHOT.tar.gz in the target folder in the cloned home directory.
2.3 Directory Structure
The structure of the target directory is as follows:
The bin directory contains three files, namely, startup.bat, startup.sh, and stop.sh, for starting and stopping programs in Windows and Linux.
The conf directory contains two configuration files. Generally, only gauss.properties is configured.
The lib directory stores the dependency files required for running.
The logs directory stores the result logs after running.
2.4 Configuration Modification
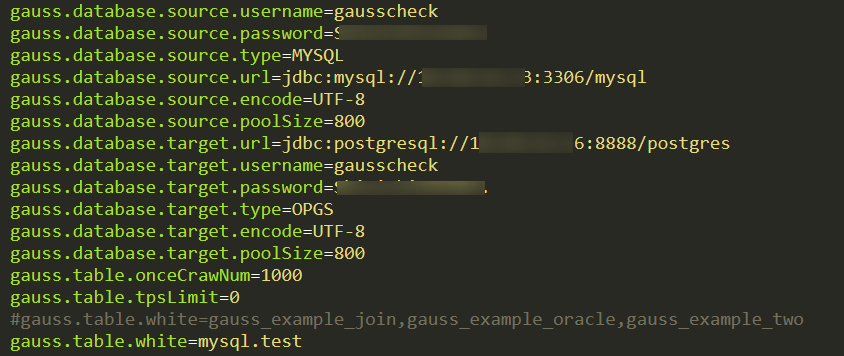
Modify the configuration in the /conf/ gauss.properties file. Generally, you only need to modify basic information, such as the addresses of the source and target databases and the tables to be verified. For other information, you can use the default values or modify it as required.
2.5 Starting and Stopping the Tool
Starting the Tool in Linux
sh startup.sh
Stopping the Tool in Linux
sh stop.sh
Starting the Tool in Windows
startup.bat
Stopping the Tool in Windows
You can directly close the terminal.
2.6 Log Description
The log structure is as follows:
The table.log file in the gauss directory records all logs in the entire verification process.
The summary.log file in the summary directory records the names of all tables whose verification results are incorrect. That is, the data in the two tables is inconsistent.
${table} indicates the name of each table. In the ${table} directory, the table.log file records all logs generated during verification of a table, the extractor.log file records all logs generated during data extraction, and the applier.log file records all logs generated during verification implementation (data comparison). The check.log file records the data that fails to be verified in a specific line. If the check.log file does not exist, the verification result is correct.
2.7 Example
Preparing the Database
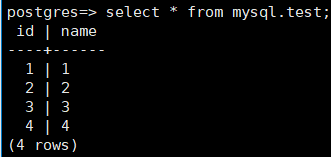
Create a table in the mysql schema in MySQL, as shown in the following figure.

Assume that after data is migrated to openGauss, only four of the five data records are successfully migrated, as shown in the following figure.
Configuring gauss.properties
Running startup.bat or startup.sh

Viewing Logs
Check the /logs/summary/summary.log file and locate the mysql.test table where the error occurs.
Access /logs/mysql.test/ to view details.
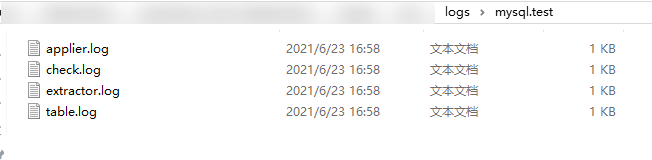
There are four log files. You can mainly view check.log.

The record whose ID is 5 and whose name is 5 fails to be migrated.