openGauss
开源数据库
openGauss社区官网
开源社区
Oracle到openGauss的SQL语句级调优
针对Oracle到openGauss迁移后的性能差异,由于SQL优化引擎的变动,我们往往需要进行语句级的SQL调优,以下我个人在实际项目中总结的一些常见的优化点。
获取执行计划
SQL调优的主要途径为根据执行计划进行SQL调优,在openGauss中可以通过explain sql获取指定SQL的执行计划
短期内可执行完成的SQL,获取实际执行计划,命令如下
explain analyze sql_text;
短期内无法执行完成的SQL,获取估算执行计划,命令如下
explain sql_text;
执行计划可视化解析工具
pev2是一款开源的优秀的Postgresql 执行计划可视化工具,我们同样可以用来进行openGauss 执行计划的呈现,下载如下html文件
https://www.github.com/dalibo/pev2/releases/latest/download/index.html
使用浏览器打开该文件,将上部获取到的执行计划文本粘贴至Plan输入框内,点击Submit,可直接生成可视化执行计划树
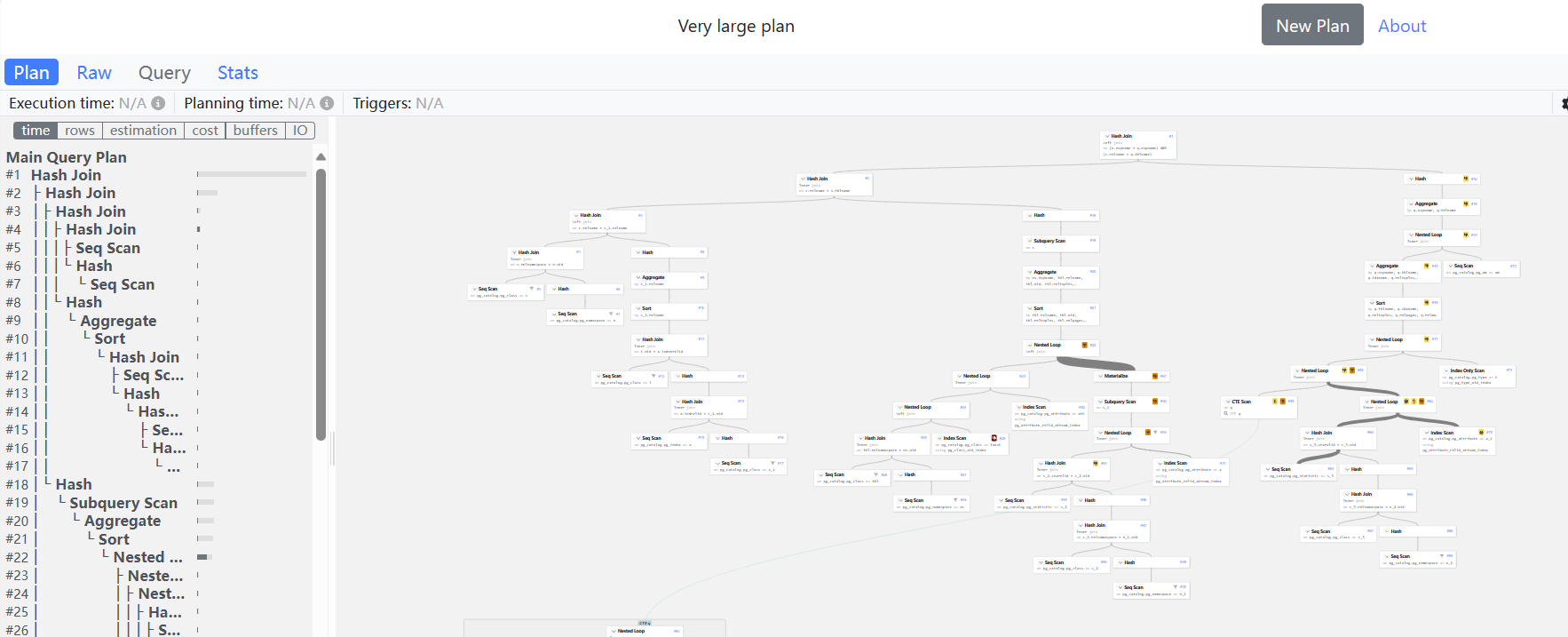
对于慢SQL,我们首要关注节点耗时,点击左侧time按钮,各节点耗时将通过条形图显示,我们选取耗时最高的sql 节点,进行分析及优化
如上样例执行计划中,耗时最高的SQL 节点如下
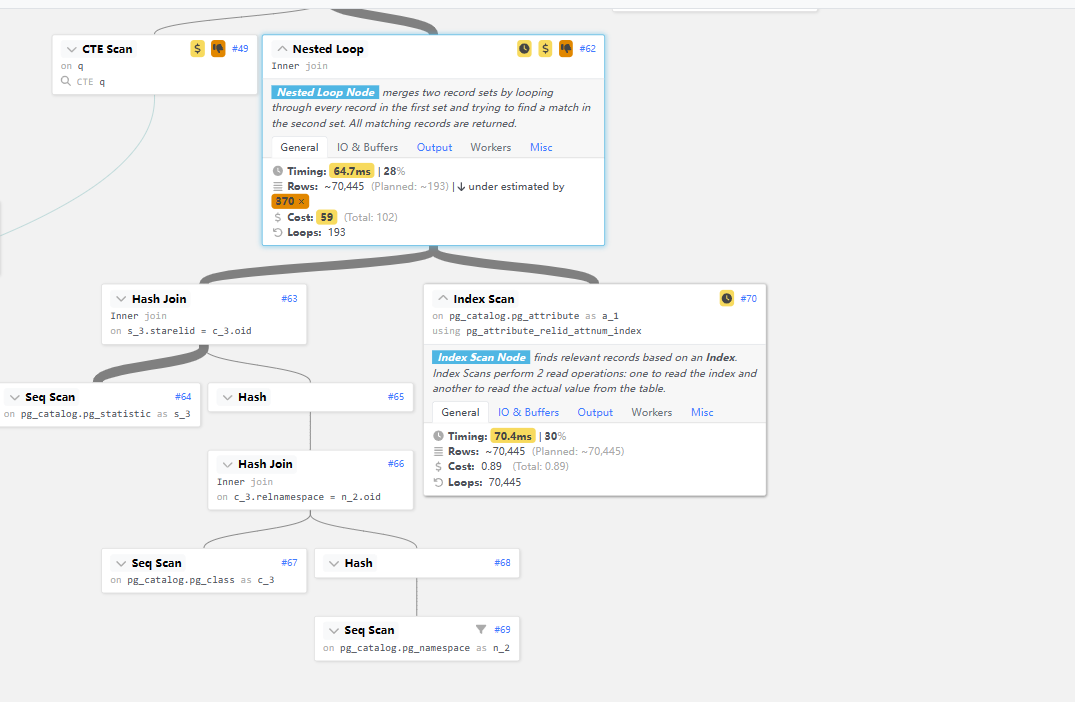
可以发现该节点下,存在大量seq scan即顺序全表扫描,如果为实际SQL,我们可以在相应表上添加索引以提升性能
常见SQL优化点
更新表统计信息
openGauss中执行计划生成依赖于表统计信息,表统计信息越及时越准确,生成的执行计划往往越精确越优。但由于表数据的更新规模与比率问题,运行时间较长的数据库中,表统计信息往往会出现偏差,导致SQL优化器错误估算代价,生成较慢的执行计划,因此,我们需要定期手工进行表统计信息的更新,执行如下命令
analyze table_name;
DBA可创建定时任务或脚本,在系统空闲期间进行重要表或全量表的统计信息刷新动作
改写SQL中的包/自定义函数引用
openGauss具备出色的oracle/mysql兼容性,目前支持自定义函数/存储过程/包等对象的使用,因而兼容在sql中引用自定义函数/包。但受限于当前执行计划优化器的解析,如果sql中引用的包/函数存在表查询操作等,执行计划无法将包/函数内的sql与外层SQL优化,导致性能极度劣化,因此,我们需要将包/函数内的SQL提取,与外层SQL结合,改写为直查的SQL以提升性能。
添加缺失的索引
重点关注执行计划中join条件(对应sql 中on子句)与filter条件(对应sql中where)子句,如果出现seq scan即全表扫描,可以考虑在相应的表字段添加合适的索引,以提升性能
类型不一致导致索引失效
在多表连接查询中,连接条件在不同表中有可能会存在数据类型不一致的情况,如A表为varchar,b表为int,即使两个字段都存在索引,也会因为类型转换导致索引失效,我们可以考虑在驱动表字段添加类型转换使索引生效
如样例 t1表 c为int,t2表c为varchar,两个字段都具有索引,在如下sql中也会失效
select t1.a,t2.b
from t1
join t2 on t2.c=t1.c
where t1.d='condition'
改写为
select t1.a,t2.b
from t1
join t2 on t2.c=t1.c::varchar
where t1.d='condition'
手工指定hint
受限于执行计划生成的智能度,部分复杂的多表关联SQL中,即使表统计信息准确、sql语法没有问题,生成的执行计划有可能不走索引,或没有进行合理的表查找顺序,针对该类情况,我们可以通过sql hint的方式,强制执行计划走最优计划 ,语法如下
/*+ <plan hint>*/
详细的hint语法,请参照openGauss官方文档
https://docs-opengauss.osinfra.cn/zh/docs/5.0.0/docs/PerformanceTuningGuide/Join%E9%A1%BA%E5%BA%8F%E7%9A%84Hint.html
子查询改写为join
针对结果集返回条数较多的SQL查询,如果select子句中存在子查询,且子查询存在索引,可以考虑将子查询改写为join,避免逐行表扫描调用,尤其是子查询存在聚合查询如count/max/min等操作
样例SQL
select t1.a,
(select max(t2.a) from t2 where t2.b=t1.b)
from t1 where t1.c='condition'
可以考虑改写为
select t1.a,
t3.max_value
from t1 where t1.c='condition'
join (select max(t2.a) max_vlaue ,t2.b from t2 group by t2.b) t3
on t3.b=t1.b
in/not in子查询改写为exists/not exists
where条件通过in/not in (select a from b)子查询进行条件过滤,执行计划往往会生成半嵌套查询,性能较差,我们可以等价改写为exists/not exists或更进一步改写为join进行优化
or条件改写为union/union all
复杂sql查询中,有可能会在where中出现or条件,如and ((xxxx and exists) or (xxxx and xxxx)),该种句式往往会存在性能问题,针对该类问题,我们可以考虑改写为union 或union all
即
select * from t1 where t1.a='condition' and ((xxxx and exists) or (xxxx and xxxx))
改写为
select * from t1 where t1.a='condition' and (xxxx and exists)
union /union all --根据是否会存在重复选取
select * from t1 where t1.a='condition' and (xxxx and xxxx)
避免视图的深层嵌套
在当前版本openGauss下,如果join表中存在视图的多重嵌套,或join 条件存在uinon等情况,SQL优化器无力将外层的过滤条件或关联条件下沉,会导致视图内查询的全表扫描,返回过大的中间结果集,导致CPU占用飙升,查询性能较慢,我们需要提取视图的定义SQL,进行等价改写
如存在视图VA,定义为
select vb.a,vb.b
from vb
join tm
on vb.c=tm.c
视图VB定义如下
select tx.a,tx.b,ty.a
from tx
left join ty
on tx.c=ty.c
存在SQL如下,该sql往往会存在性能问题
select t1.*,va.*
from t1
join va
on va.a=t1.a
where t1.b='condition'
改写如下
select t1.*,va.*
from t1
join (select vb.a,vb.b
from (select tx.a,tx.b,ty.a
from tx
left join ty
on tx.c=ty.c ) vb
join tm
on vb.c=tm.c) va
on va.a=t1.a
where t1.b='condition'
他山之石可以攻玉
对于原oracle数据库执行性能正常而openGauss性能劣化的SQL,如果单纯分析openGauss执行计划无法发现性能瓶颈或优化点,我们可以考虑参照oracle的执行计划进行比对,发现openGauss执行计划中的问题,从而进行SQL优化