openGauss
开源数据库
openGauss社区官网
开源社区
MogDB Query执行流程
MogDB Query 执行流程
本文出处:https://www.modb.pro/db/31227
简介
SQL 引擎从接受 SQL 语句到执行 SQL 语句需要经历的步骤如图 1 和说明 1 所示。其中,红色字体部分为 DBA 可以介入实施调优的环节。
图 1 SQL 引擎执行查询类 SQL 语句的流程
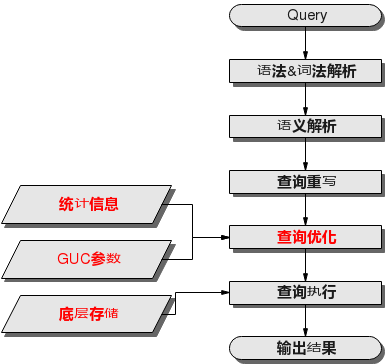
说明 1 SQL 引擎执行查询类 SQL 语句的步骤说明
1、语法&词法解析
按照约定的 SQL 语句规则,把输入的 SQL 语句从字符串转化为格式化结构(Stmt)。
2、语义解析
将"语法&词法解析"输出的格式化结构转化为数据库可以识别的对象。
3、查询重写
根据规则把"语义解析"的输出等价转化为执行上更为优化的结构。
4、查询优化
根据"查询重写"的输出和数据库内部的统计信息规划 SQL 语句具体的执行方式,也就是执行计划。统计信息和 GUC 参数对查询优化(执行计划)的影响,请参见调优手段之统计信息和调优手段之 GUC 参数。
5、查询执行
根据"查询优化"规划的执行路径执行 SQL 查询语句。底层存储方式的选择合理性,将影响查询执行效率。详见调优手段之底层存储。
调优手段之统计信息
MogDB 优化器是典型的基于代价的优化(Cost-Based Optimization,简称 CBO)。在这种优化器模型下,数据库根据表的元组数、字段宽度、NULL 记录比率、distinct 值、MCV 值、HB 值等表的特征值,以及一定的代价计算模型,计算出每一个执行步骤的不同执行方式的输出元组数和执行代价(cost),进而选出整体执行代价最小/首元组返回代价最小的执行方式进行执行。这些特征值就是统计信息。从上面的描述可以看出统计信息是查询优化的核心输入,准确的统计信息将帮助规划器选择最合适的查询规划,一般来说我们通过 analyze 语法收集整个表或者表的若干个字段的统计信息,周期性地运行 ANALYZE,或者在对表的大部分内容做了更改之后马上运行它是个好习惯。
调优手段之 GUC 参数
查询优化的主要目的是为查询语句选择高效的执行方式。
如下 SQL 语句:
select count(1)
from customer inner join store_sales on (ss_customer_sk = c_customer_sk);
在执行 customer inner join store_sales 的时候,MogDB 支持 Nested Loop、Merge Join 和 Hash Join 三种不同的 Join 方式。优化器会根据表 customer 和表 store_sales 的统计信息估算结果集的大小以及每种 join 方式的执行代价,然后对比选出执行代价最小的执行计划。
正如前面所说,执行代价计算都是基于一定的模型和统计信息进行估算,当因为某些原因代价估算不能反映真实的 cost 的时候,我们就需要通过 guc 参数设置的方式让执行计划倾向更优规划。
调优手段之底层存储
MogDB 的表支持行存表、列存表,底层存储方式的选择严格依赖于客户的具体业务场景。一般来说计算型业务查询场景(以关联、聚合操作为主)建议使用列存表;点查询、大批量 UPDATE/DELETE 业务场景适合行存表。
对于每种存储方式还有对应的存储层优化手段,这部分会在后续的调优章节深入介绍。
调优手段之 SQL 重写
除了上述干预 SQL 引擎所生成执行计划的执行性能外,根据数据库的 SQL 执行机制以及大量的实践发现,有些场景下,在保证客户业务 SQL 逻辑的前提下,通过一定规则由 DBA 重写 SQL 语句,可以大幅度的提升 SQL 语句的性能。
这种调优场景对 DBA 的要求比较高,需要对客户业务有足够的了解,同时也需要扎实的 SQL 语句基本功,后续会介绍几个常见的 SQL 改写场景。