openGauss
开源数据库
openGauss社区官网
开源社区
如何利用shardingSphere-proxy搭建openGauss分布式环境
一、 shardingSphere-proxy 简介
shardingSphere-proxy(以下简称为"proxy")定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前提供 MySQL 和 PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
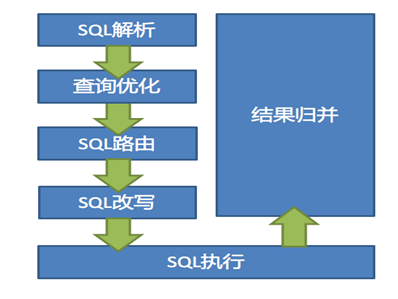
proxy 实现分布式的核心原理是,使用 netty 捕获客户端(gsql 或 jdbc)的 sql 语句,通过抽象语法树解析 sql,根据配置的分库分片规则,改写 sql 语句,使其路由到对应的数据库上并聚合多个 sql 的返回结果,再将结果通过 netty 返回给客户端,这样就完成了分库分片的全流程,如下图示:
二、 shardingSphere-proxy 获取
proxy 默认支持 PostgreSQL 协议,openGauss 也采用的是 PostgreSQL 协议,但是二者的认证方式和批量插入协议有区别。为了能使 proxy 正常工作,需要向 lib 目录中增加 openGauss 的 jdbc 驱动,此驱动可以从 maven 中央仓库下载,坐标是:
<groupId>org.opengauss</groupId>
<artifactId>opengauss-jdbc</artifactId>
目前需要从 master 分支自行编译:链接,本示例为从 openGauss 分支上 自己编译出包。
说明:shardingsphere-5.1.1 及以上版本又合入 openGauss 驱动,不需要再额外下载驱动。
三、 搭建 openGauss 分布式环境
1 解压二进制包
获取二进制包后,可以通过tar -zxvf命令进行解压,解压后的内容如下:

2 替换为 openGauss jdbc(5.1.1 及以上版本忽略此步骤)
进入到 lib 目录下,并且将原有的 postgresql-42.2.5.jar 删除,将 opengauss-jdbc 的 jar 放置在该目录下即可。
3 修改 server.yaml
进入 conf 目录, 该目录下已经有 server.yaml 文件的模板。该配置文件的主要作用是配置前端的认证数据库、用户名和密码, 以及连接相关的属性:包括分布式事务类型、sql 日志等。
当然 proxy 还支持 zookeeper 和 etcd 配置中心,它可以从配置中心读取配置或者永久保存配置,本次使用暂不涉及其使用。
server.yaml 最简配置如下:
rules:
- !AUTHORITY
users:
- root@%:root
- sharding@:sharding
provider:
type: ALL_PRIVILEGES_PERMITTED
props:
max-connections-size-per-query: 1
executor-size: 16 # Infinite by default.
proxy-frontend-flush-threshold: 128 # The default value is 128.
4 修改 config-sharding.yaml
进入 conf 目录,该目录下已经有 config-sharding.yaml 文件的模板。该文件主要作用是配置后端与 openGauss 数据库的连接属性,分库分表规则等。
本次分片示例为,数据分两个库,表分为 3 片,数据库分片键为 ds_id,值按 2 取余,表分片键为 ts_id,值按 3 取余。
分库后插入数据分布如下:
| ds_id | ts_id | 前端 schema | 前端表名 | 后端数据库 | 后端表 |
|---|---|---|---|---|---|
| 0 | 0 | sharding_db | t1 | ds_0 | t1_0 |
| 0 | 1 | sharding_db | t1 | ds_0 | t1_1 |
| 0 | 2 | sharding_db | t1 | ds_0 | t1_2 |
| 1 | 0 | sharding_db | t1 | ds_1 | t1_0 |
| 1 | 1 | sharding_db | t1 | ds_1 | t1_1 |
| 1 | 2 | sharding_db | t1 | ds_1 | t1_2 |
config-sharding.yaml 极简配置如下:
dataSources:
ds_0:
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 10000
maintenanceIntervalMilliseconds: 10000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
minPoolSize: 10
password: ******@***
url: jdbc:opengauss://90.90.44.171:44000/ds_0?serverTimezone=UTC&useSSL=false&connectTimeout=10
username: test
ds_1:
connectionTimeoutMilliseconds: 10000
idleTimeoutMilliseconds: 10000
maintenanceIntervalMilliseconds: 10000
maxLifetimeMilliseconds: 1800000
maxPoolSize: 200
minPoolSize: 10
password: ******@***
url: jdbc:opengauss://90.90.44.171:44000/ds_1?serverTimezone=UTC&useSSL=false&connectTimeout=10
username: test
rules:
- !SHARDING
defaultDatabaseStrategy:
none: null
defaultTableStrategy:
none: null
shardingAlgorithms:
ds_t1_alg:
props:
algorithm-expression: ds_${ds_id % 2}
type: INLINE
ts_t1_alg:
props:
algorithm-expression: ts_${ts_id % 3}
type: INLINE
tables:
t1:
actualDataNodes: ds_${0..1}.ts_${0..2}
databaseStrategy:
standard:
shardingAlgorithmName: ds_t1_alg
shardingColumn: ds_id
tableStrategy:
standard:
shardingAlgorithmName: ts_t1_alg
shardingColumn: ts_id
schemaName: sharding_db
5 启动 shardingSphere-proxy
进入 bin 目录,以上配置完成后,使用sh start.sh即可启动 proxy 服务,默认绑定 3307 端口。可以在启动脚本时使用sh start.sh 4000修改为 4000 端口。
四、 环境验证
要想确认 proxy 是否正确启动,请查看 logs/stdout.log 日志,当存在提示成功启动日志后即成功。
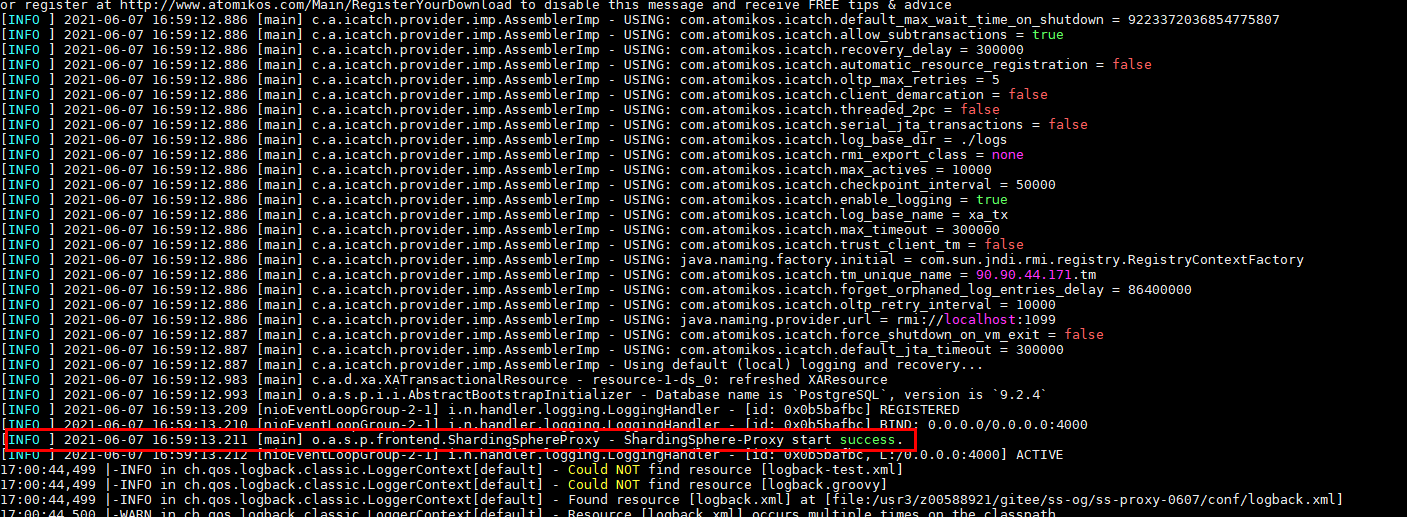
在 opengauss 数据库上使用gsql -d sharding_db -h $proxy_ip -p 3307 -U sharding -W sharding -r即可连接数据库。
五、 分布式数据库使用
上面的部署已经确认 proxy 环境可用了,那么连上 gsql 就可以对分布式数据进行操作了,默认已经使用 gsql 连接上终端了。
1 新建表
在 gsql 终端中执行create table t1 (id int primary key, ds_id int, ts_id int, data varchar(100));即可创建表,它的语法不需要任何修改。
2 增删改
- 增:
insert into t1 values (0, 0, 0, 'aaa') - 删:
delete from t1 where id = 0 - 改:
update t1 set data = 'ccc' where ds_id = 1;
以上语法不需要任何修改即可执行
3 查
select * from t1 即可获取所有的数据,在 proxy 中简单的 select 语句几乎不需要修改语法即可执行。
复杂的查询语法(如二次子查询)当前支持的不是很完整,可以持续向 shardingSphere 社区提交 issue 来更新。
4 事务
shardingSphere 事务使用方法与原来的方式一致,依然通过 begin/commit/rollback 来实现。