openGauss
开源数据库
openGauss社区官网
开源社区
openGauss数据库SQL解析模块源码分析
openGauss 数据库 SQL 解析模块源码分析
一.概述
经过对 openGauss 安装使用后发现 openGauss 依然采用 sql 语言进行数据库操作。于是我对 openGauss 如何使用 sql 的语法进行数据库操作进行了探索。 通过学习已有博客分析和源码的阅读,我发现这个过程在 SQL 引擎中算作 SQL 解析,SQL 语句在数据库管理系统中的编译过程符合编译器实现的常规过程,需要进行词法分析、语法分析和语义分析。 (1) 词法分析:从查询语句中识别出系统支持的关键字、标识符、操作符、终结符等,确定每个词自己固有的词性。常用工具如 flex。 (2) 语法分析:根据 SQL 语言的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个 SQL 语句能够匹配一个语法规则,则生成对应的抽象语法树(abstract synatax tree,AST)。常用工具如 Bison。 (3) 语义分析:对抽象语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为查询树。 所以个人感觉内容和编译原理实验差不多。 openGauss 采用 flex 和 bison 两个工具来完成词法分析和语法分析的主要工作。对于用户输入的每个 SQL 语句,它首先交由 flex 工具进行词法分析。flex 工具通过对已经定义好的词法文件进行编译,生成词法分析的代码。
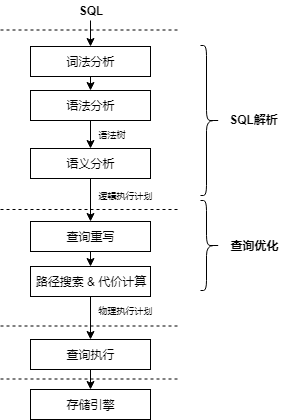
二.SQL 解析的具体实现分析
###1.代码结构
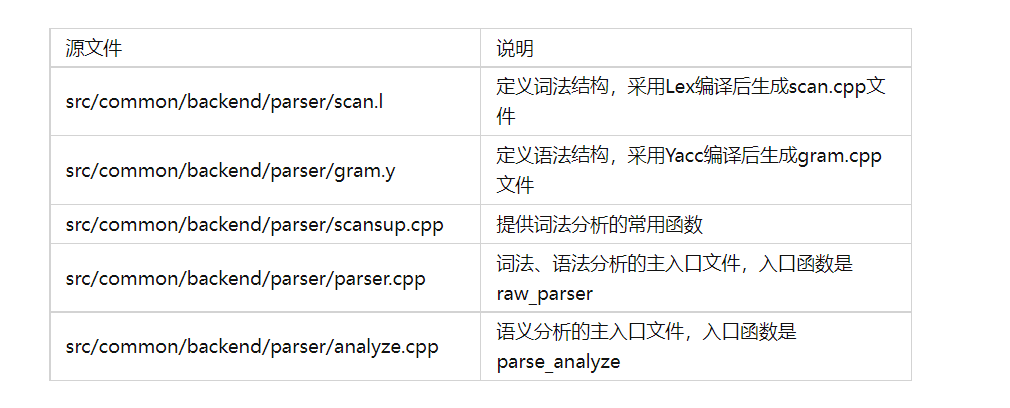 词法结构和语法结构分别由 scan.l 和 gram.y 文件定义,并通过 flex 和 bison 分别编译成 scan.cpp 和 gram.cpp 文件。 ###2.词法分析 openGauss 中的词法文件是 scan.l,它根据 SQL 语言标准对 SQL 语言中的关键字、标识符、操作符、常量、终结符进行了定义和识别。 词法分析将一个 SQL 划分成多个不同的 token,每个 token 会有自己的词性。 ####(1)函数声明
词法结构和语法结构分别由 scan.l 和 gram.y 文件定义,并通过 flex 和 bison 分别编译成 scan.cpp 和 gram.cpp 文件。 ###2.词法分析 openGauss 中的词法文件是 scan.l,它根据 SQL 语言标准对 SQL 语言中的关键字、标识符、操作符、常量、终结符进行了定义和识别。 词法分析将一个 SQL 划分成多个不同的 token,每个 token 会有自己的词性。 ####(1)函数声明 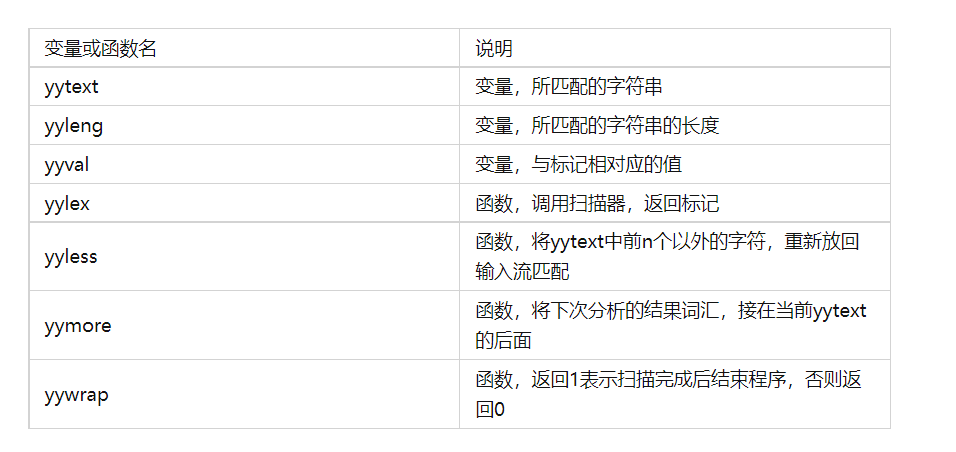


####(2)flex 文件构成 Flex 文件由三个部分组成。或者说三个段。三个段之间用两个%%分隔。 定义段(definitions) %% 规则段(rules) %% 用户代码段(usercode)
####(3)定义段分析(token 定义) 1)空格,换行,注释  2)op tokens 是单个 char 还是具有特殊操作的识别(看 op tokens 后面还有更多字符)
2)op tokens 是单个 char 还是具有特殊操作的识别(看 op tokens 后面还有更多字符) 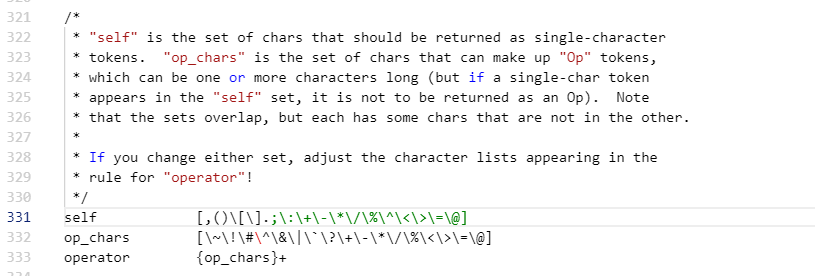 3)数据类型定义
3)数据类型定义 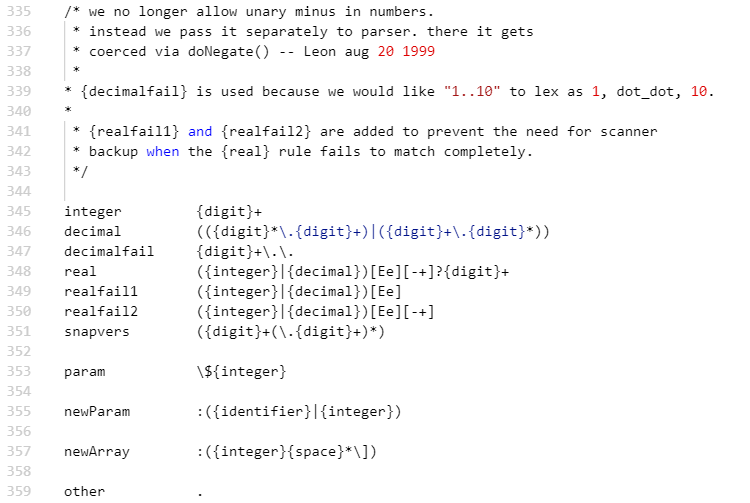
4)其他 还有关于括号识别确定 sql 语句开始或结束(包括{ }double quote 和$ $style quote),注释识别(c style)等。
####(4)规则段分析(识别 token 后的操作) 1)只有空格则什么都不做 
 2)sql 单语句操作时,将分号前的所有字符视为一条 sql 操作语句存储起来。(识别单语句取决于是否在括号里)
2)sql 单语句操作时,将分号前的所有字符视为一条 sql 操作语句存储起来。(识别单语句取决于是否在括号里) 

####(5)用户代码段分析
1)Report a lexer or grammar error cursor position(光标位置错误处理) 
###3.语法分析 openGauss 中定义了 bison 工具能够识别的语法文件 gram.y,同样在 Makefile 中可以通过 bison 工具对 gram.y 进行编译,生成 gram.cpp 文件。 openGauss 中,根据 SQL 语言的不同定义了一系列表达 Statement 的结构体(stmt),用来保存语法分析结果(如 SELECT,DELETE,CREATE)。
源码分析 gram.y openGauss/openGauss-server - Gitee IDE ####(1)Bison 语法文件内容的布局 Bison 语法文件内容的分布如下(四个部分): %{ 序言 %} Bison 声明 %% 语法规则 %% 结尾
####(2)序言(prologue)分析
####(3)Bison 声明 1)通过 %pure_parser 来指定希望解析器是可重入的。(默认情况下 yyparse() 函数是没有参数的, 可以通过%parse-param {param} 来传递参数, 调用的时候也是 yyparse(param)的形式. %lex-param 是对 yylex() 函数增加参数. 
2)Bison 中默认将所有的语义值都定义为 int 类型,可以通过定义宏 YYSTYPE 来改变值的类型。如果有多个值类型,则需要通过在 Bison 声明中使用%union 列举出所有的类型 
3)非终结符使用%type 来定义 
4)终结符使用%token 
5)操作符优先级(左结合,右结合) 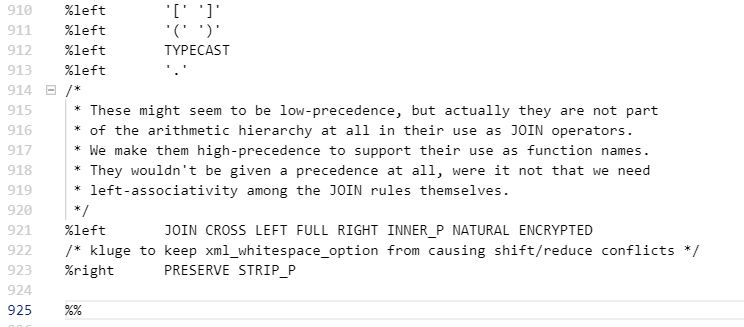
####(4)语法规则(grammar rules) 1)编译目标  2)所有语法规则结构体
2)所有语法规则结构体 
3)具体功能实现 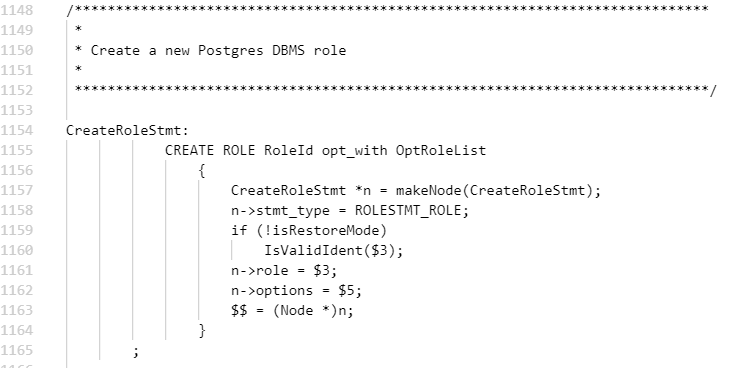
####(5)结尾 
###4.flex 与 bison 的联系 用 bison 来做语法分析,首先要将分析对象做仔细的研究。分析工作的首要任务是分清楚什么是终结符,什么是非终结符。 终结符是一组原子性的单词,表达了语法意义中不可分割的一个标记。在具体的表现形式上,可能是一个字符串,也可能是一个整数,或者是一个空格,一个换行符等等。bison 只给出每个终结符的名称,并不给出其定义。Bison 为每个终结符名称分配一个唯一的数字代码。 终结符的识别由专门定义的函数 yylex()执行。这个函数返回识别出来的终结符的编码,且已识别的终结符可以通过全局变量 yytext 指针,而这个终结符的长度则存储在全局变量 yyleng 中。来取得这种终结符的分析最好用 flex 工具通过对语法文件进行扫描来识别。有些终结符有不同的具体表示。 非终结符是一个终结符序列所构成的一个中间表达式的名字。实际上不存在这么一个原子性的标记。这种非终结符的构成方式则应该由 Bison 来表达。语法规则就是由终结符和非终结符一起构成的一种组成规则的表达。 Bison 实际上也是一个自动化的文法分析工具,其利用词法分析函数 yylex()返回的词法标记返回其 ID,执行每一条文法规则后定义的动作。Bison 是不能自动地生成词法分析函数的。一般简单的程序里,一般在文法规则定义文件的末尾添加该函数的定义。但是在较复杂的大型程序里,则利用自动词法生成工具 flex 生成 yylex()的定义。 Bison 与 Flex 联用时,Bison 只定义标记的 ID。Flex 则需要知道这些词法标记的 ID,才能在识别到一个词法标记时返回这个 ID 给 Bison。Bison 传递这些 ID 给 Flex 的方法,就是在调用 bison 命令时使用参数-d。使用这个参数后,Bison 会生成一个独立的头文件,该文件的名称形式为 name.tab.h。在 Flex 的词法规则文件中,在定义区段里包含这个头文件即可。 yylex()只需要每次识别出一个 token 就马上返回这个 token 的 ID 即可。上例中返回的 token 的 ID 就是 TOK_NUMBER。此外,一个 token 的语义值可以由 yylex()计算出来后放在全局变量 yylval 中。
##三.总结 对 openGauss 内核分析的任务,我选择了看起来较为熟悉的 SQL 解析模块。在博客文章的指引下成功找到了对应模块所在位置,之后便开始拜读大佬们的程序。因为之前也用 flex 和 bison 做过编译原理的实验作业,所以整个步骤大概还知道点。代码写的真好,注释啥的都很多,主要问题就是注释也全英文,看的那叫一个难受。由于里面有很多专业词汇,谷歌翻译的一团糟,很多看完大概知道什么意思,但不确定理解的对不对。感觉专业词汇可能见多了才能舒服的阅读,我现在明显还没这个功力。
##四.参考资料 1.https://zhuanlan.zhihu.com/p/389174538 2.https://gitee.com/opengauss/openGauss-server/tree/master/src/common/backend/parser 3.https://www.cnblogs.com/me115/archive/2010/10/27/1862180.html