openGauss
开源数据库
openGauss社区官网
开源社区
openGauss的MVCC以及vacuum机制源码解析—CSN LOG
openGauss 的 MVCC 以及 vacuum 机制源码解析—CSN LOG
背景介绍
openGauss 数据库于 2020 年 6 月 30 日开源,当时就下载了该数据库的源代码,但因为其他重要项目工作的原因,一直没有抽出时间对其进行研究。最近,项目阶段性任务已经完成,现对其进行简浅地学习跟研究。业内人士可能都了解过,openGauss 数据库是基于 PostgreSQL 研发出来的,应该也知道 openGauss/PostgreSQL 跟 MySQL 等数据库最大的区别是 MVCC 以及 vacuum 的机制不同,作者也非常想了解这块的内容。所以,研究 openGauss 的时候,就从这块内容入手。
openGauss 数据库中包含表数据文件,clog(事务提交状态日志,commit Log ), CSN(COMMIT SEQUENCE NUM)日志,VM 文件等等。提到的这些文件跟 MVCC 以及 VACUUM 机制有直接的关系,是实现这两个功能的基石。(对于 openGauss/postgreSQL 的 MVCC 以及 vacuum 机制的基本原理还不太了解的朋友,可以先查阅相关的资料,例如《openGauss 数据库核心技术》书籍中介绍 MVCC 以及 VACUUM 机制的章节。虽然 MVCC 以及 VACUUM 的机制的原理很简单,但是,如果深挖,细节却非常的多。因为介绍原理的资料已经很多,所以我们不再去重复写关于这两个机制的实现原理的文章。我们将介绍机制的实现细节。鉴于这两个功能模块的实现细节多而且复杂,作者没法一口气写完所有内容,读者们也不太可能有这么大片的时间去读完,所以采用类似于写长篇小说的那种模式,分章节去介绍.单独阅读某个章节,可能会相对比较片面,所以建议读者朋友们提前了解 mvcc 以及 vacuum 机制的基本原理以及所涉及的各个模块。
CSN LOG 解析
本篇将介绍有关 MVCC 的最小的一个模块 CSN LOG 的实现,这个模块就是数据库内部的逻辑时钟,可以用来判断某条记录是否对当前执行的 SQL 可见。因为判断一个记录对当前 SQL 是否可见,不能单纯地以产生该条记录的事务是否已经提交来判断,即使已经提交,也得判断该事务是否在当前 SQL 的快照时钟之前提交,如果是之前提交,则可见。如果是之后提交,则不可见。
CSN(COMMIT SEQUENCE NUM) 日志,采用全局自增的长整数作为逻辑的时间戳,模拟数据库内部的时序,当 SQL 执行的时候,首先会获取一个快照时间戳 snapshot,当扫描数据页面的时候,会根据 snapshot.CSN 和事务状态来判断哪个元组(记录)版本可见,或者都不可见。这句话非常简单,也很好理解。但是该如何实现?实现时需要考虑哪些问题?
- CSN 是一个自增长的数值,但如何建立事务跟这个数值之间的关系。
- 数据库会一直执行事务,如果要记录每个事物的 CSN,该怎么存放这些信息。
- 因为判断一行记录的提交时间戳,也就是该条记录对应的事务号(xmin 或者 xmax)所对应的 CSN 很可能是否高频操作,所以如何快速获取这个信息?
带着这些问题,我们来逐步解析源代码,来寻找答案。
首先找到第一个问题的答案, CSN 是一个步长为 1 的自增长的全局变量,在事务提交阶段,获取该值。
653 CommitSeqNo getNextCSN()
654 {
655 returnpg_atomic_fetch_add_u64(&t_thrd.xact_cxt.ShmemVariableCache->nextCommitSeqNo,1);
656 }

上一步是获取即将提交完成的事务的 CSN 号,接下来,将保存这个事务的 CSN 号,具体如何保存?继续往下看。
通过 CSNlogSetCSN 函数,将 xid(事务号)所对应的提交时间戳(CSN)保存下来。
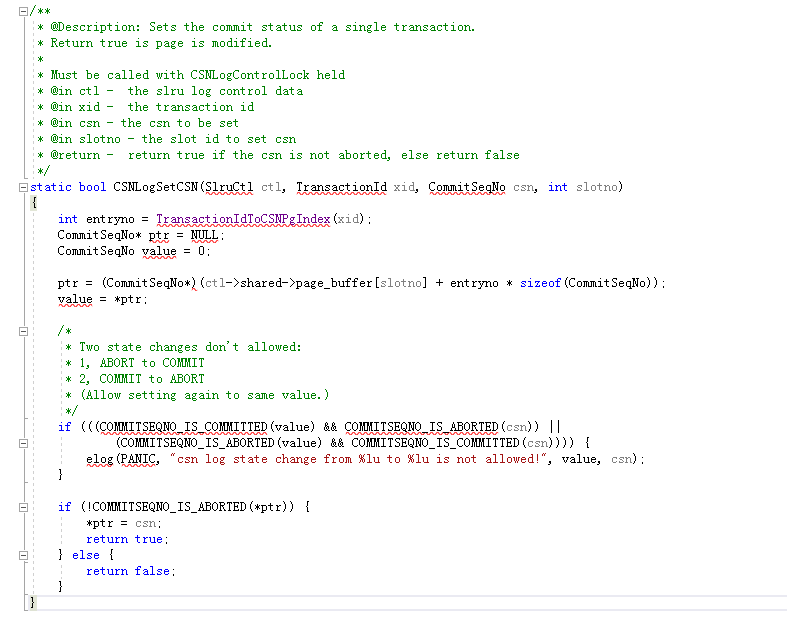
上面的函数,已体现出如何将 SCN 保存下来,以及通过 int entryno = TransactionIdToCSNPgIndex(xid); 该代码, 知道事务号跟页面的 offset 之间的关系,TransactionIdToCSNPgIndex 宏定义如下:#defineTransactionIdToCSNPgIndex(xid) ((xid) % (TransactionId)CSNLOG_XACTS_PER_PAGE) ,通过 #defineCSNLOG_XACTS_PER_PAGE (BLCKSZ sizeof(CommitSeqNo)) 知道 CSNLOG_XACTS_PER_PAGE 为 1024,即 8K/8。
页面内 offset 的值为 485=27109 % 1024
382 ptr= (CommitSeqNo*)(ctl->shared->page_buffer[slotno] + entryno *sizeof(CommitSeqNo));
(gdb) l
377 {
378 intentryno = TransactionIdToCSNPgIndex(xid);
379 CommitSeqNo* ptr = NULL;
380 CommitSeqNo value = 0;
381
382 ptr= (CommitSeqNo*)(ctl->shared->page_buffer[slotno] + entryno *sizeof(CommitSeqNo));
383 value = *ptr;
384
385 *
386 *Two state changes don't allowed:
(gdb) p entryno
$4 = 48
而根据事务号计算保存该事务的 CSN 的页面号的计算方法,由这个宏确定:
#defineTransactionIdToCSNPage(xid) ((xid) (TransactionId)CSNLOG_XACTS_PER_PAGE) , 因为一个 CSN 占据 8 字节,所以 8K 的页面可以保存 1024 个 CSN 号。根据事务号 27109/1024 得到的页面号就是 26(请参考下面调试堆栈图的第二行,pageno=26) 。在数据库中,对于文件的修改,都是基于 WAL 的原则,即在 buffer 中完成修改并记录日志即可(对临时文件页面的修改例外,可以不记日志)。所以需要根据 pageno=26,找到对应的在内存中的页面,即 slotno,然后在内存中完成修改即可。

解析到这里,基本回答了前面提到的 3 个问题。对第二个问题在延伸一下,我们知道一个 8K 的页面可以保存 1024 个事务的 CSN。如果数据库已经执行了 10 亿个事务,我们来计算一下所需要的空间:1000000000/1024=976562,即 976562 个 8K 的页面,共 7812496K,高斯数据库已经将事务号修改成 64 位,如果是 100 亿的事务号,则需要 78124960K,将会消耗大量的空间。因此,需要有清理机制,清理不再需要的 CSN 日志,这个清理的任务由 checkpoint 线程来完成。请看下面的堆栈:

清理工作,由函数 TruncateCSNLOG 来完成,该函数唯一的入参为 oldestxact , 也就是最小的活跃事务号,事务号小于该值的事务,对任何用户会话都是可见的,所以它们的 CSN 记录是可以清理的。
下面我们来解析这个 TruncateCSNLOG 函数:
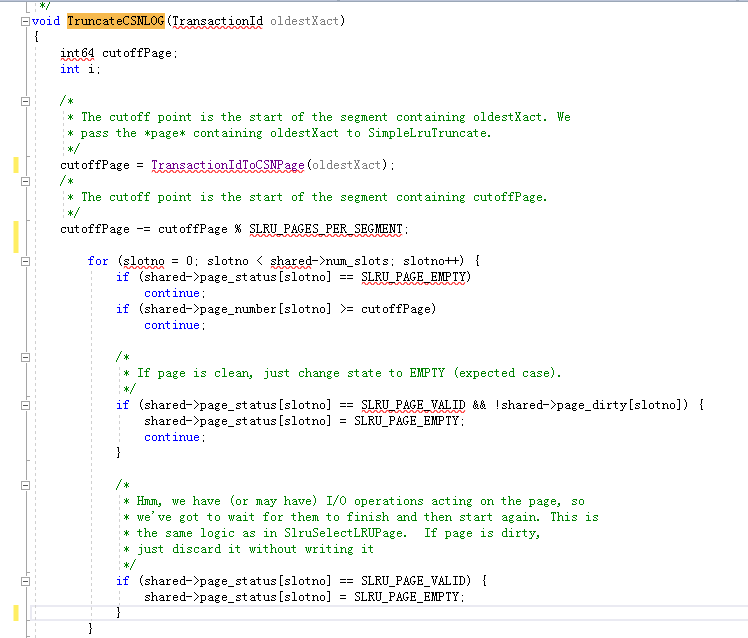
(注:为了显示方便,以上代码删除了非关键逻辑的代码)。
该函数首先根据 oldestXact 值(也就是事务号),定位到清除 CSN 日志页面的终止位置(cutoffPage) ,在清除页面之前,需要将相关页面设置为 SLRU_PAGE_EMPTY. 如果页面号大于 cutoffPage ,则跳过 (这两行代码 if(shared->page_number[slotno] >= cutoffPage);continue; 为 pageno 大于 cutoffpage 的页面进行跳过处理)。因为页面号大于 cutoffpage 的页面,记录着事务号大于 oldestXact 的事务的 CSN,当前 SQL 可能需要使用到这些 SCN 的信息,用来判断某条记录(行)对当前执行的 SQL 是否可见。为什么在清理文件之前,需要将相关的页面设置为 SLRU_PAGE_EMPTY?这是为了释放缓存,因为文件即将被删除,所以在 buffer 中的页面也将设置为 SLRU_PAGE_EMPTY 状态,也就是将对应的页面设置为空闲页面,以便 buffer 中的页面可以重新利用。
设置完相关页面的状态之后,调用 SlruScanDirCbDeleteCutoff 进行清理。我们来看看 SlruScanDirCbDeleteCutoff 函数的栈:
SlruScanDirCbDeleteCutoff 函数代码:

调用 unlink 函数,将 csn log 的文件删除,以段为单位进行删除。
关于 CSN 日志文件的工作机制的实现细节到这里基本解析完毕,希望看完此篇文章后,对理解这块内容所有帮助。