openGauss
开源数据库
openGauss社区官网
开源社区
openGauss SQL解析源码分析
openGauss SQL 解析源码分析
SQL 引擎简介:
SQL 引擎整个编译的过程如下图所示,在编译的过程中需要对输入的 SQL 语言进行词法分析、语法分析、语义分析,从而生成逻辑执行计划,逻辑执行计划经过代数优化和代价优化之后,产生物理执行计划。
SQL 解析通常包含词法分析、语法分析、语义分析几个子模块。SQL 是介于关系演算和关系代数之间的一种描述性语言,它吸取了关系代数中一部分逻辑算子的描述,而放弃了关系代数中"过程化"的部分,SQL 解析主要的作用就是将一个 SQL 语句编译成为一个由关系算子组成的逻辑执行计划。<img src='https://img-blog.csdnimg.cn/20c9730d6b754a57b2e145a25fc8b47d.png?x-oss-process,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAcXFfNDQzNjExMzY=,size_15,color_FFFFFF,t_70,g_se,x_16)
数据库的 SQL 引擎是数据库重要的子系统之一,它对上负责承接应用程序发送过来的 SQL 语句,对下则负责指挥执行器运行执行计划。其中优化器作为 SQL 引擎中最重要、最复杂的模块,被称为数据库的"大脑",优化器产生的执行计划的优劣直接决定数据库的性能。右图为 SQL 引擎的各个模块的响应过程。下图的绿色部分代表解析树的生成,;蓝色部分代表查询树的生成部分。
<img src='https://img-blog.csdnimg.cn/c5e36efb9b22452c9aed5f746586897d.png?x-oss-process,type_ZHJvaWRzYW5zZmFsbGJhY2s,shadow_50,text_Q1NETiBAcXFfNDQzNjExMzY=,size_19,color_FFFFFF,t_70,g_se,x_16)
理论分析
SQL 解析各模块功能介绍:
假设要在 student 表里找到查找序号为 1 的学生姓名,其 SQL 语句如下:
Select name
from student where no=1
- 词法分析:
从查询语句中识别出系统支持的关键字、标识符、运算符、终结符等,确定每个词固有的词性。分析结果如下图所示,可以看到一个 SQL 语句按一个一个的字词或符号分开,形成可以被解读语义的字符。
| 词性 | 内容 |
|---|---|
| 关键字 | Select、from、where |
| 标识符 | name、student、no |
| 操作符 | = |
| 常量 | 1 |
(2)语法分析:
根据 SQL 的标准定义语法规则,使用词法分析中产生的词去匹配语法规则,如果一个 SQL 语句能够匹配一个语法规则,则生成对应的抽象语法树(AST)。
下图中的<projection>代表投影,<relation>代表关系,即查询来源那些表,<condition>代表条件,一般是一些表达式。
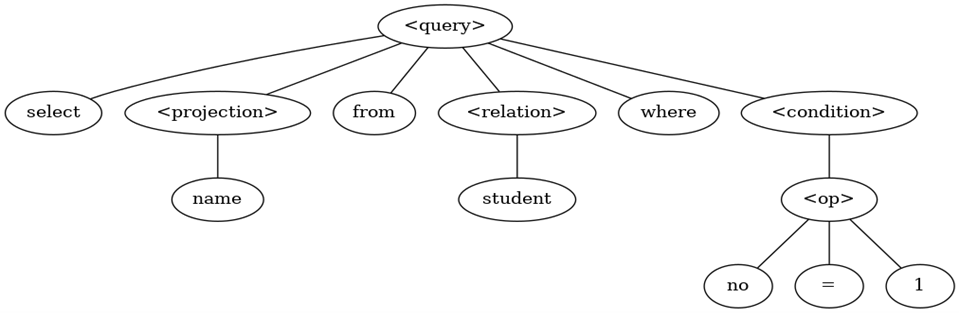
(3)语义分析:
对语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为逻辑执行计划(关系代数表达式)。在 SQL 标准中,确定了 SQL 的关键字以及语法规则信息,对语法树进行有效性检查,检查语法树中对应的表、列、函数、表达式是否有对应的元数据,将抽象语法树转换为逻辑执行计划(关系代数表达式),即查询树。可由右图的关系表达式来呈现: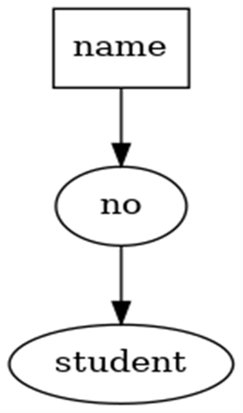
代码分析
3.1 总体流程
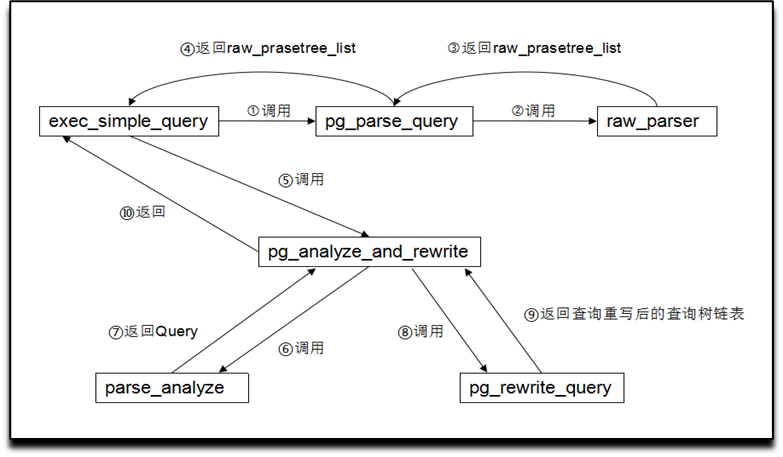
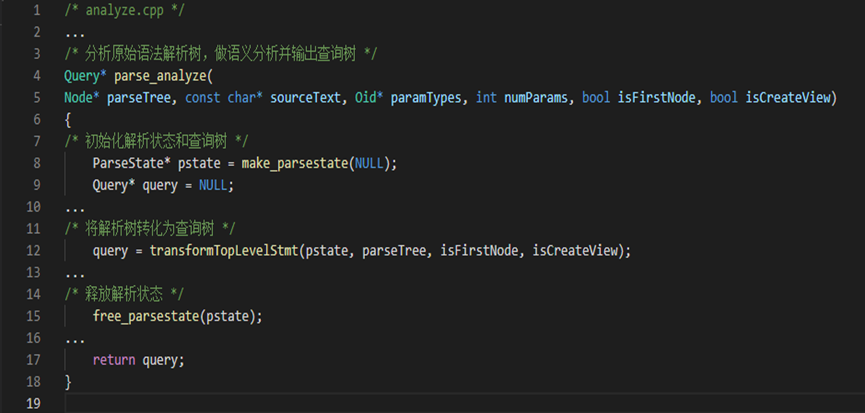
exec_simple_query 函数是整个过程的主函数,调渡解析中的所有过程,主函数调用函数 pg_parse_query 进入词法分析和语法分析的主过程,函数 pg_parse_query 再调用词法分析和语法分析的入口函数 raw_parser 生成分析树;之后返回分析树(raw_parsetree_list)给 exec_simple_query 函数;exec_simple_query 函数调用查询与重写函数,查询与重写函数再调用 paser_analyze 函数进行语义分析返回查询树链表 query,最后将查询树链表传递给查询重写模块,最后返回给 exec_simple_query 主函数。
3.2 词法分析
(1)openGauss 中的词法文件是 scan.l,它根据 SQL 语言标准对 SQL 语言中的关键字、标识符、操作符、常量、终结符进行了定义和识别。代码如下图:
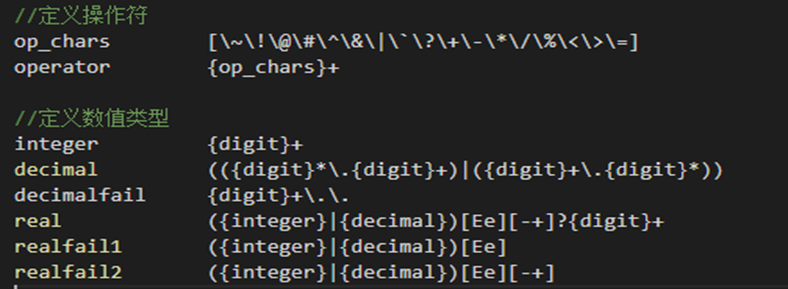
(2)下图是词法分析涉及到的关键字原型,由三部分组成,分别是名字、Token 值、类别。名字是字符串原型,Token 值是一个 int 型的数。openGauss 在 kwlist.h 中定义了大量的关键字,按照字母的顺序排列,方便在查找关键字时通过二分法进行查找。

3.3 语法分析:
解析树的节点定义如下:
(1)仅在叶节点出现的的一些基本属性(一些常见的属性会在后面介绍)
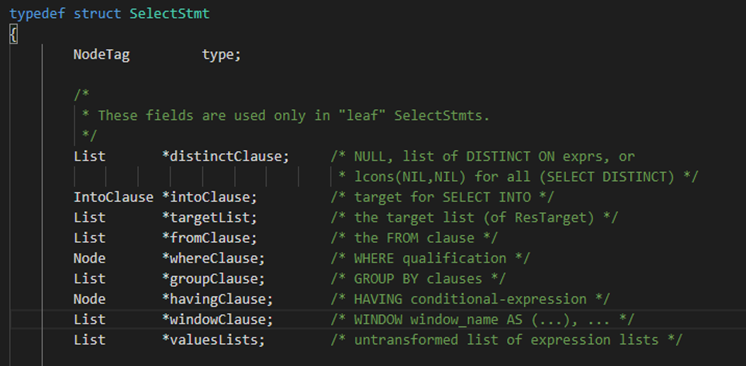
(2)下图的属性不仅用于叶节点还能用于更上层的非叶子节点
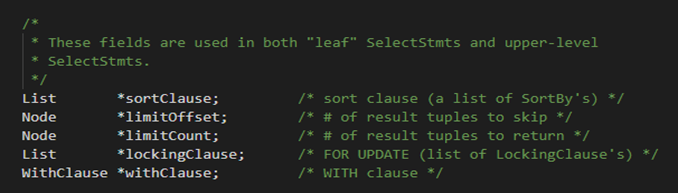
(3)下图部分的属性值及用于非叶子节点
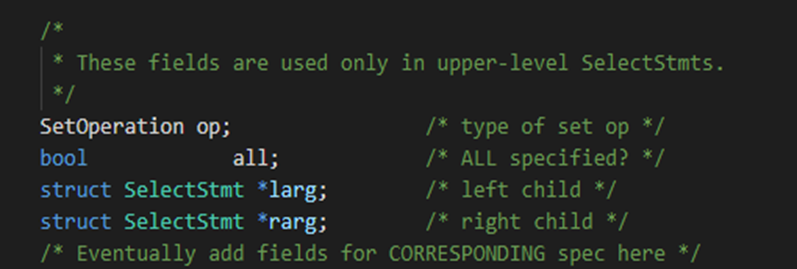
原始解析树的生成(完成语法和词法分析后生成的多叉树):
对于下面的 SQL 查询语句: 
完成语法分析后生成的原始解析树如下(蓝色部分分别于上述语句各部分相对应):
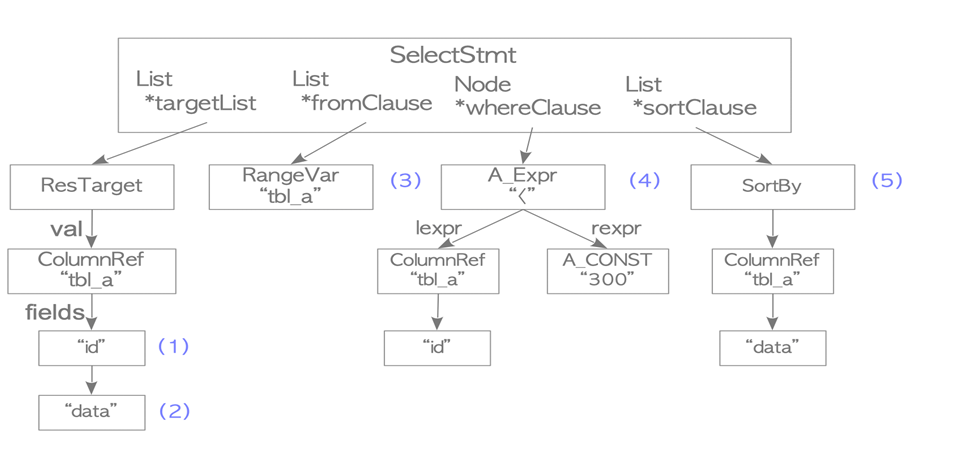
targetList:最后查询完成显示的目标列
fromClause:from 子句,标识该查询来自某个或某些表。
whereClause:where 子句,一般接一些条件表达式,表示查询条件
sortClause:sort by 子句节点,如果需要按照某一列排序时会用到。
需要注意的是,由于解析器仅在生成解析树时检查输入的语法,因此只有在查询中出现语法错误时才会返回错误。解析器不检查输入查询的语义。例如,即使查询包含不存在的表名,解析器也不会返回错误。语义检查由分析器(analyse.cpp)完成。
3.4 语义分析
(1)总体流程:进入到 analyze.cpp 进行语义分析,将所有语句转换为查询树供重写器和计划器进一步处理。
输入:原始语法解析树 parseTree 和源语句 sourceText
输出:查询树 query
(2)查询树节点的定义:
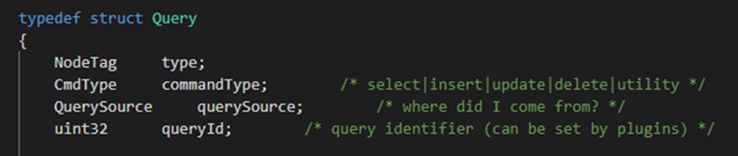
上图是查询树节点的基础属性部分,也是大部分语句都共有的部分,表示 SQL 语句的类型(增删改查),来源和标识号等等;
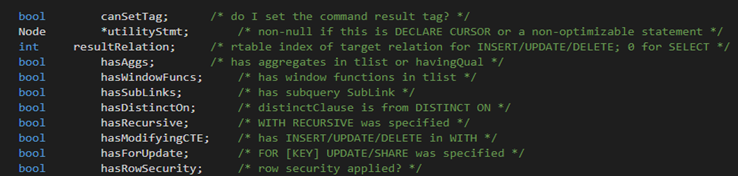
上图为查询树节点的第二部分定义 bool 类型的变量,表示该查询的相关属性,例如有无子语句,是否需要去重等等。 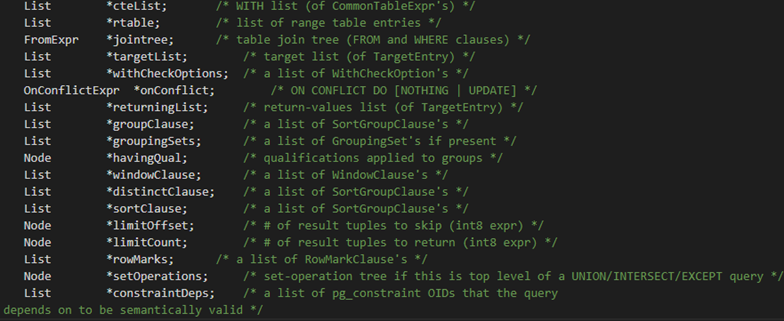
上图为查询树节点的第三部分定义。主要用于表示目标列表,from 子句,where 子句等的节点或链表。
3.5 查询树的生成和可视化
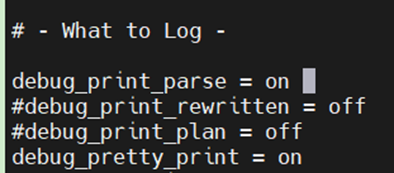
第一步,修改/opt/software/openGauss/data/single_node 目录下的配置文件 postgresql.conf 中的配置项 debug_print_parse 即可在日志文件中打印查询树
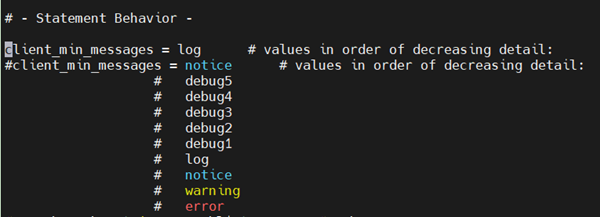
第二步,修改 client_min_messages 为 log(如下图),以便可以在客户端输出语法树。
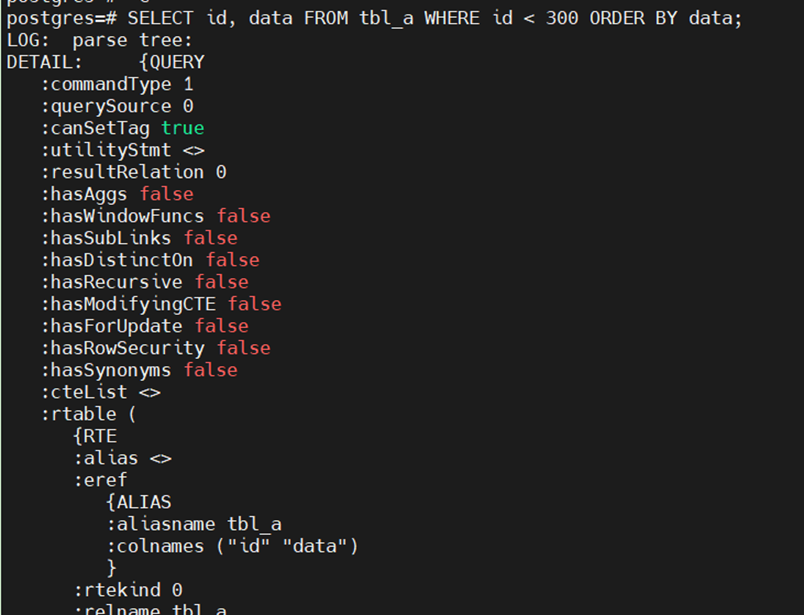
之后我们可以看到客户端生成的输出语法树如下:
最后,利用开源工具(https://github.com/shenyuflying/pgNodeGraph)可以把客户端输出的查询树可视化,如下图: 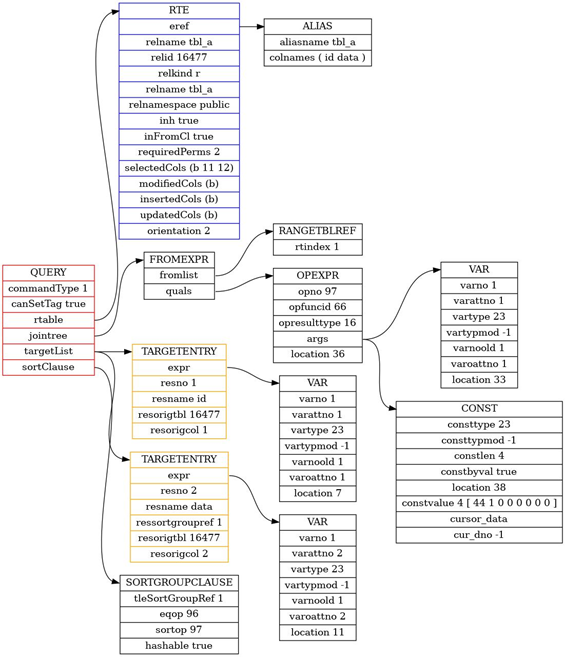
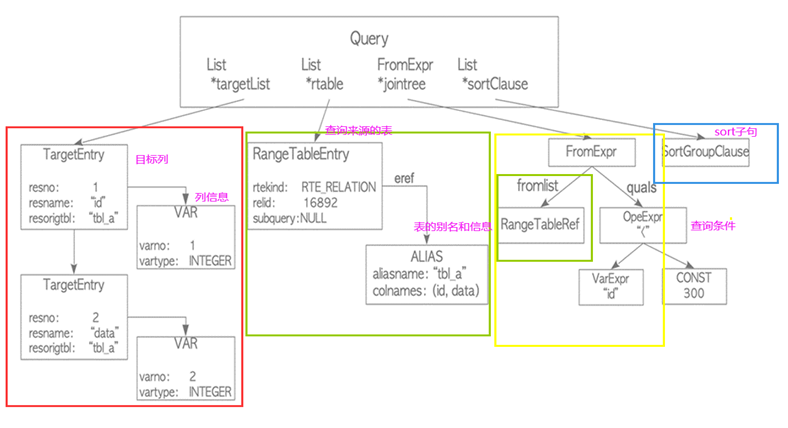
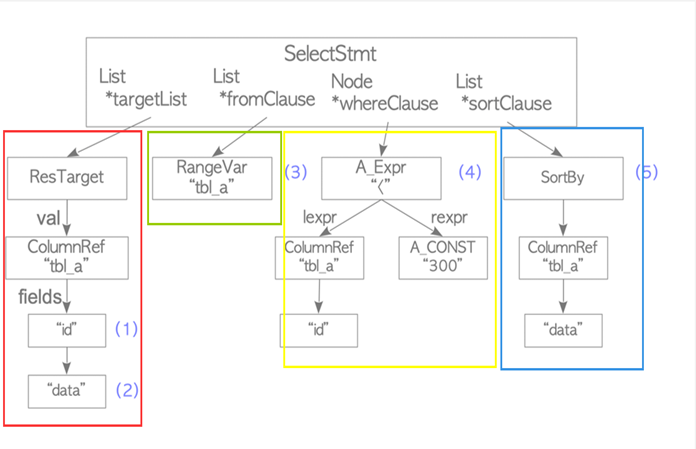
对比语法分析后所生成的解析树(下图 1)和语义分析后生成的查询树(下图 2,已简化)不难看出其节点结构的变化,
红框部分是目标列表,对应查询语句中的 select 子句,即查询完成后需要显示的某一或某几属性列。
绿框部分代表查询来源的表,主要对应的是查询语句中的 from 子句,在查询树生成时候还会附带表的别名和其他信息。
黄框部分在解析树时候主要对应 where 子句的节点,其中 A_Expr 代表运算符号,ColumnRef 是该属性(id)源自哪张表,A_CONST 代表的比较子句的常量;而在查询树时 from 子句和 where 子句会合并为一个 jointree 节点。
蓝框部分主要是一些其他的 sort,having 等子句的节点主要做排序等作用。
图一
图二